
Un Large Language Model, abreviado LLM, es un modelo lingüístico basado en aprendizaje automático que, mediante el entrenamiento con amplias colecciones de textos, es capaz de analizar entradas en lenguaje natural, reaccionar a ellas y generar de forma autónoma textos coherentes y contextuales.
- Desarrollo histórico
- Funcionamiento y tecnología
- Entrenamiento y datos
- Arquitectura
- Prompts como interfaz
- Medir la visibilidad en LLM con SISTRIX
- Áreas de aplicación típicas de los LLM
- Generación automática de textos
- Comunicación con usuarios
- Procesamiento de grandes cantidades de información
- Análisis y clasificación de datos
- Áreas especializadas
- Integración en motores de búsqueda
- Desafíos y riesgos
- Problema del grounding
- Sesgos y alucinaciones
- Prompt injections
- Huella ecológica
- Incertidumbres legales
- Riesgo de uso indebido
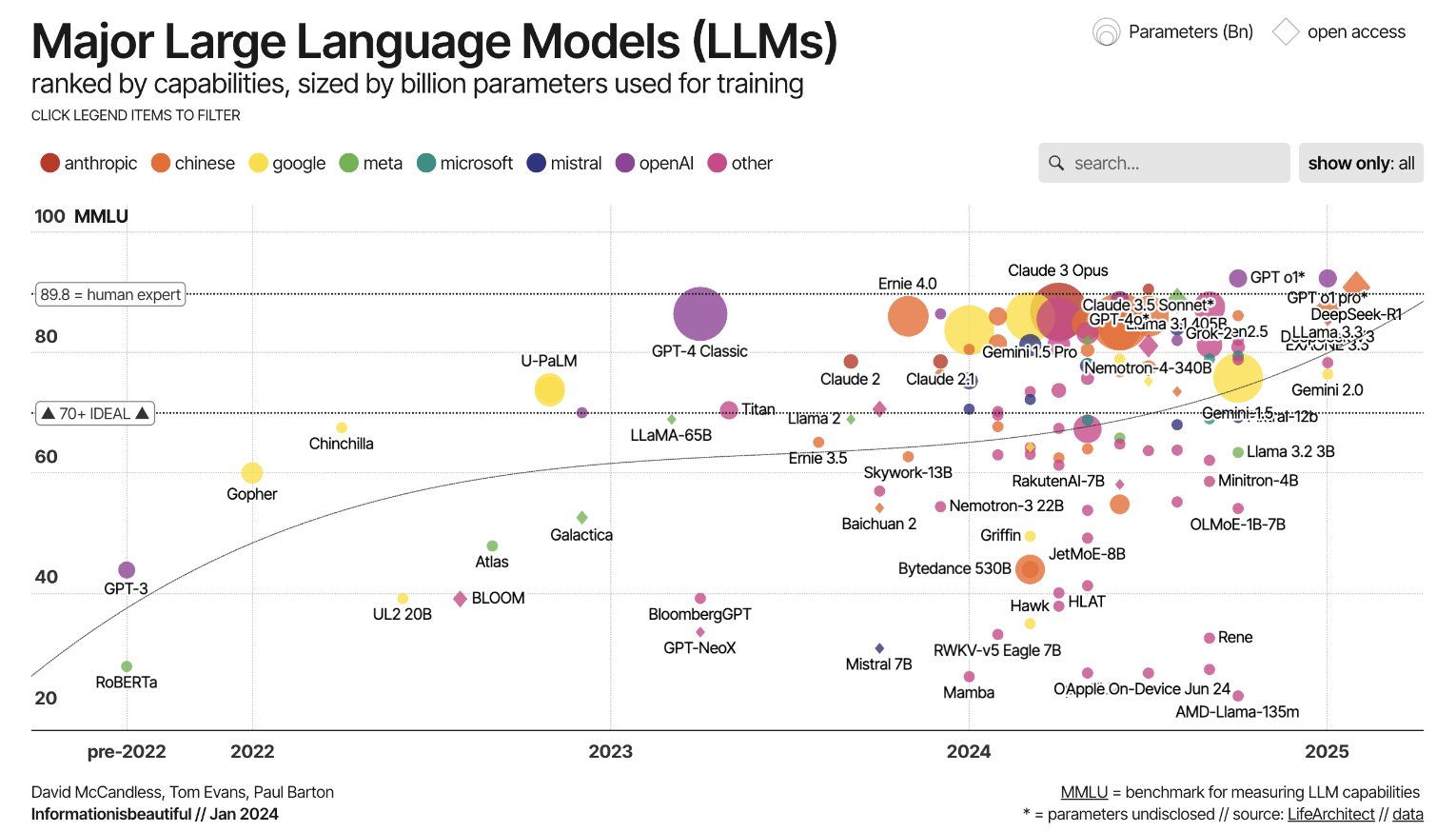
- Ejemplos de Large Language Models conocidos
- LLM y motores de búsqueda
- Motores de búsqueda tradicionales
- Ventajas de los LLM
- Adaptación de los proveedores
- Relevancia de la búsqueda tradicional
- Implicaciones para SEO
Los Large Language Models son sistemas informatizados que procesan lenguaje a gran escala: analizan patrones lingüísticos en textos y generan contenidos basándose en probabilidades estadísticas que suelen resultar convincentes para los lectores humanos, aunque el modelo en sí no comprende el contenido en sentido humano.
Lo característico es que se entrenan con enormes cantidades de datos. Textos de libros, páginas web, artículos, comentarios, etc. y en el proceso aprenden cómo funciona el lenguaje: gramática, estilo, contexto, significado y relaciones.
Sin embargo, esto no significa que los modelos lingüísticos “lo sepan todo”; solo han sido expuestos a cantidades muy grandes de conocimiento humano y únicamente pueden extraer información a partir de esos datos.
Desarrollo histórico
El desarrollo de los modelos lingüísticos comenzó con sistemas simples basados en reglas que solo podían reconocer contextos limitados. Más tarde surgieron modelos que, con ayuda de la Inteligencia Artificial, aprendían a procesar mejor el lenguaje. Estas primeras redes neuronales supusieron avances iniciales, pero aún no eran especialmente potentes con textos más largos o contextos complejos.
El verdadero hito llegó con la arquitectura Transformer en 2017. Esta hizo posible procesar de forma eficiente cantidades muy grandes de datos y, al mismo tiempo, captar contextos textuales más extensos. Sobre esta base surgieron los Large Language Models actuales, significativamente más potentes, flexibles y completos que sus predecesores.
La arquitectura Transformer desempeña un papel central: permite que el modelo no solo observe localmente un punto concreto del texto, sino que pueda relacionar todas sus partes entre sí mediante mecanismos de auto-atención (self-attention). Así se captan contextos lingüísticos de forma mucho más integral, se resuelven mejor las ambigüedades y se aplican de forma más coherente estilo y significado. La evolución hacia los LLM no consiste únicamente en más datos y potencia de cálculo, sino en mejoras fundamentales en la arquitectura del modelo.
Funcionamiento y tecnología
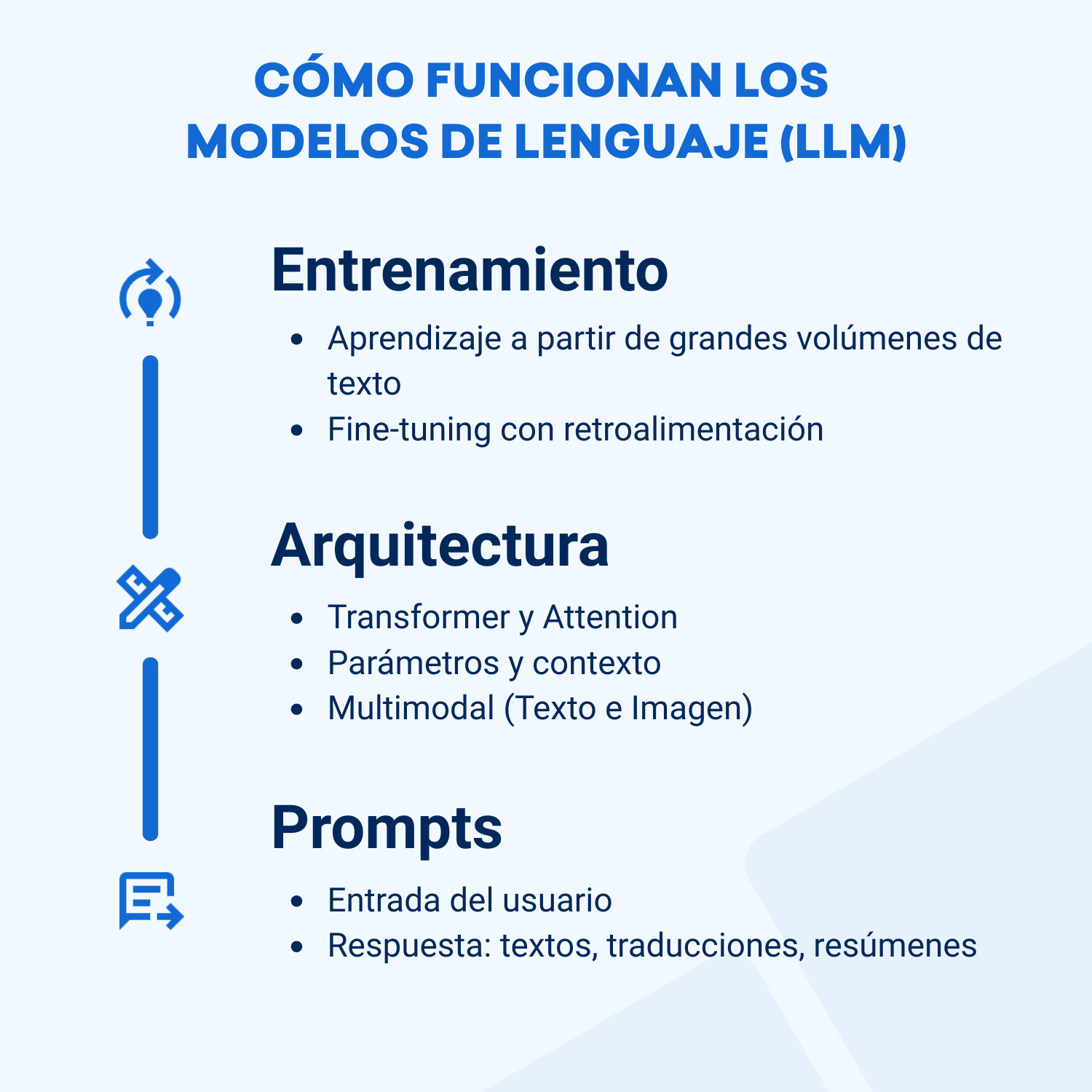
Entrenamiento y datos
El entrenamiento de un LLM comienza típicamente con una fase de pre-entrenamiento (pre-training), comparable con una educación general básica. Para ello se utilizan grandes corpus de textos variados: libros, publicaciones científicas, noticias, foros, etc. El objetivo en esta fase no es resolver tareas específicas, sino aprender patrones lingüísticos: ¿cómo construyen las personas las frases?, ¿cómo conectan ideas?, ¿cómo se genera el significado más allá de las palabras? Esta fase es autosupervisada: el modelo intenta, por ejemplo, predecir la siguiente palabra o reconstruir partes faltantes en una frase.
Tras el pre-training suele seguir una fase de ajuste (fine-tuning), en la que el modelo se adapta a tareas o dominios específicos. Por ejemplo, un LLM puede ajustarse para comprender textos jurídicos, apoyar conversaciones médicas o interactuar con clientes como chatbot. Además, se emplean métodos como instruction tuning, donde el modelo aprende a seguir instrucciones, y reinforcement learning from human feedback (RLHF), en el que el feedback humano mejora calidad, claridad y seguridad de las respuestas.
Arquitectura
La mayoría de los LLM modernos se basan en la arquitectura Transformer. Esta permite al modelo observar simultáneamente todas las palabras de un texto y reconocer sus relaciones entre sí. Un componente central es el mecanismo de atención (attention), que ayuda al modelo a determinar qué palabras de una frase son especialmente relevantes para comprender el contexto.
La potencia de un modelo depende, entre otras cosas, del número de parámetros: valores ajustables mediante los cuales el modelo aprende. Cuantos más parámetros tiene un modelo, más complejas pueden ser las relaciones que representa, aunque también aumenta el coste técnico del entrenamiento y uso.
Otra propiedad esencial es la longitud de contexto: determina cuánta cantidad de texto puede tener en cuenta el modelo simultáneamente. Con contextos cortos, se pierde rápidamente la coherencia; los modelos modernos, en cambio, pueden procesar artículos completos o conversaciones largas sin perder el hilo conductor.
Además, existen LLM multimodales que procesan no solo texto, sino también imágenes u otros tipos de datos. Pueden, por ejemplo, describir una imagen, interpretar un gráfico o responder a una pregunta que se refiere a una combinación de texto e imagen. Esto amplía considerablemente las posibilidades de aplicación, por ejemplo en la descripción de productos, el servicio al cliente o el análisis de contenidos visuales.
Prompts como interfaz
El uso de los LLM se basa en los llamados prompts. Un prompt es la entrada que un usuario proporciona al modelo: una pregunta, instrucción o fragmento de texto. El modelo procesa ese prompt y genera una respuesta adecuada. Pequeñas variaciones en la formulación pueden influir notablemente en la salida. A través de prompts también pueden introducirse grandes volúmenes de datos, por ejemplo textos completos para revisión, clasificación o traducción.
Medir la visibilidad en LLM con SISTRIX
Los LLM como ChatGPT, Gemini o DeepSeek están cambiando cómo las personas encuentran información y cómo las marcas se hacen visibles. Cada vez más consultas que antes generaban clics ahora se responden directamente mediante chatbots, motores de búsqueda de IA o AI Overviews de Google. Esto reduce los clics y cambia los KPI relevantes. Lo que antes eran visitas y clics, ahora se convierte en menciones, citas y enlaces dentro de respuestas generadas por IA.
Con SISTRIX AI Chatbot Beta ya puedes medir estas nuevas métricas. Puedes comprobar en qué chatbots se menciona una marca, en qué prompts aparece la propia entidad y dónde, en cambio, solo aparecen competidores.
A pesar de estos cambios, la mayoría de las búsquedas siguen pasando por Google, y esto no cambiará a corto plazo, por lo que muchas estrategias del SEO clásico siguen siendo válidas y constituyen la base correcta en el nuevo entorno de los LLM.
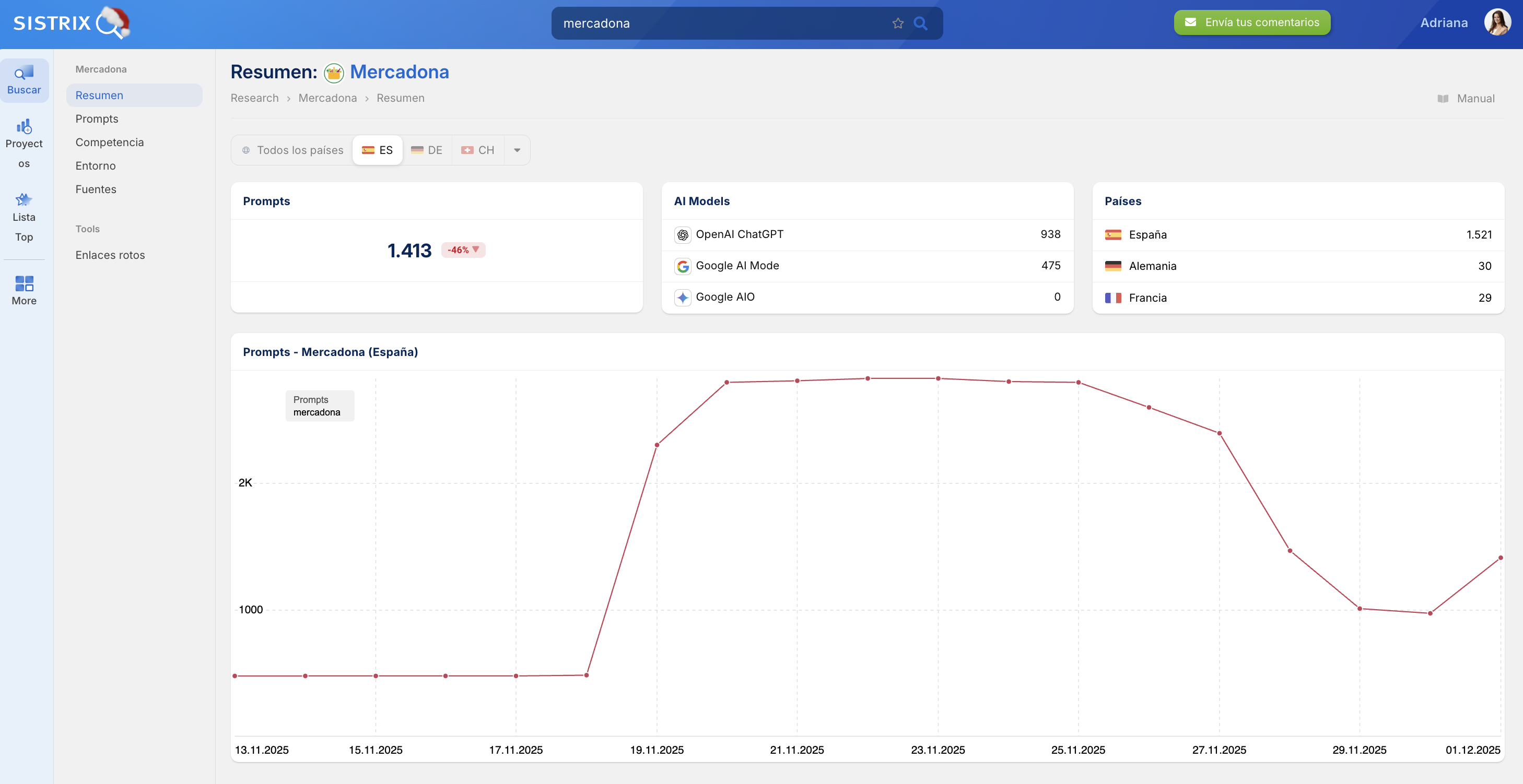
Quien quiera mantener su visibilidad deberá trabajar no solo en estrategias SEO operativas, sino sobre todo en análisis. Prueba SISTRIX gratis durante 14 días y descubre qué tan visible es tu marca en sistemas de búsqueda generativos.
Áreas de aplicación típicas de los LLM
Los LLM encuentran aplicación en muchos campos, en parte en escenarios cotidianos, en parte en especializados.
Generación automática de textos
Una de las aplicaciones más evidentes. Desde artículos de blog hasta textos de marketing, correos electrónicos o contenido creativo. Los LLM pueden generar borradores útiles que aceleran la edición humana.
Comunicación con usuarios
Los LLM se utilizan como chatbots o asistentes virtuales: responden preguntas, dan recomendaciones, mantienen diálogos y dan soporte. Mejoran la experiencia de usuario y permiten escalabilidad en servicio al cliente.
Procesamiento de grandes cantidades de información
Pueden resumir, extraer ideas clave, responder preguntas complejas o estructurar información. Son valiosos en investigación, documentación empresarial, ciencia o análisis jurídico.
Análisis y clasificación de datos
Se emplean para sentiment analysis, agrupación temática, clasificación de textos, detección de tendencias y riesgos en redes sociales o análisis de feedback.
Áreas especializadas
Existen LLM adaptados a dominios como medicina, derecho o finanzas, con mayores exigencias de precisión, rastreabilidad y fiabilidad.
Integración en motores de búsqueda
Una tendencia creciente es su integración en la búsqueda: los motores ya no solo ofrecen enlaces, generan respuestas directas basadas en lenguaje a consultas de búsqueda. Los motores de búsqueda se convierten en motores de respuestas. Así surge una nueva forma de búsqueda de información en la que ya no está en primer plano la navegación hacia contenidos, sino la comprensibilidad inmediata y la facilidad de uso. Los modelos actúan aquí como interfaz entre usuario y conocimiento y cambian fundamentalmente cómo se perciben y procesan los resultados de búsqueda.
Desafíos y riesgos
Por muy potentes que sean, los LLM presentan riesgos importantes.
Problema del grounding
Un problema fundamental es la falta de grounding: los modelos lingüísticos calculan probabilidades, pero no tienen comprensión del mundo real. Aunque sistemas con conexión web como ChatGPT o Gemini incluyen información actual de páginas web, no verifican hechos, sino que siguen generando respuestas sobre una base puramente lingüística.
Sesgos y alucinaciones
De ahí resultan sesgos (bias) y alucinaciones (hallucinations). Las distorsiones en los datos de entrenamiento conducen a salidas discriminatorias o estereotípicas, mientras que las alucinaciones pueden generar informaciones aparentemente plausibles pero falsas, con consecuencias potencialmente graves en áreas sensibles como medicina o derecho. Los LLM no pueden clasificar correctamente los hechos y responden a todo prompt, incluso si este ya está formulado de forma errónea o con sesgo.
Prompt injections
Otro riesgo son las prompt injections. Aquí, atacantes intentan inducir a los modelos, mediante entradas preparadas o páginas web manipuladas, a eludir especificaciones de seguridad o revelar datos confidenciales. Estos ataques son especialmente difíciles de asegurar, ya que no afectan al código sino al propio nivel lingüístico.
Huella ecológica
El entrenamiento y operación de modelos grandes consumen enormes recursos computacionales y energéticos.
Incertidumbres legales
Derechos de autor, protección de datos y propiedad del contenido generado siguen sin resolverse plenamente.
Riesgo de uso indebido
Los LLM pueden emplearse para desinformación, spam o manipulación a gran escala.
Las oportunidades son significativas, pero requieren regulación, transparencia e investigación continua.
Ejemplos de Large Language Models conocidos
Algunos de los LLM más conocidos son los siguientes:
- Los modelos GPT (OpenAI) cuentan entre los más utilizados. Ofrecen un fuerte rendimiento en producción generativa de lenguaje y tienen un amplio respaldo mediante herramientas, integraciones y recursos de la comunidad.
- Los modelos LLaMA (Meta) son frecuentemente abiertos (al menos en parte), se utilizan en investigación y en escenarios de aplicación especializados y permiten adaptaciones a requisitos específicos.
- Gemini (Google DeepMind) es una familia de modelos que existe desde diciembre de 2023 y se considera sucesora de LaMDA y PaLM. Gemini comprende variantes como Gemini Ultra, Gemini Pro, Gemini Flash y Gemini Nano. Se trata de modelos multimodales, es decir, aquellos que además de texto también pueden procesar otras modalidades como imágenes. Una propiedad especialmente notable de Gemini es la ventana de contexto muy grande.
- Claude (Anthropic) es un modelo lingüístico que se desarrolla desde 2023. Se basa en el enfoque de «Constitutional AI» (IA constitucional), en el que el comportamiento del modelo se controla mediante un conjunto de reglas establecido. Claude ha aparecido en varias generaciones (Claude 1, 2 y 3) y se desarrolla continuamente.
LLM y motores de búsqueda
Con la creciente capacidad de los LLM surge una pregunta central que actualmente se discute intensamente: ¿Reemplazan los Large Language Models a los motores de búsqueda clásicos?
Motores de búsqueda tradicionales
Los motores de búsqueda tradicionales como Google o Bing se basan en el núcleo en el rastreo, indexación y valoración de páginas web. Los usuarios introducen términos de búsqueda, reciben una lista de resultados y hacen clic para llegar a contenidos relevantes. Esta interacción está orientada a la información, pero es fragmentada: el usuario sigue siendo responsable de filtrar informaciones, verificar fuentes y combinar contenidos por sí mismo.
Ventajas de los LLM
Los LLM, por el contrario, ofrecen una interfaz directa basada en lenguaje, lo que hace más simple la usabilidad. No proporcionan listas de enlaces, sino respuestas (supuestamente) terminadas, a menudo con resúmenes, argumentos o contexto. La experiencia del usuario cambia: en lugar de «Encuentra información sobre X», ahora está en primer plano «Explícame X». Así, la tarea se desplaza del «buscar» hacia el «comprender». En muchos escenarios «inequívocos», es decir, en preguntas para las que solo hay una respuesta correcta, por ejemplo en preguntas sencillas de conocimiento, explicaciones de conceptos o instrucciones de acción, los LLM ya reemplazan hoy casi completamente la búsqueda web clásica.
Adaptación de los proveedores
Esto también cambia el comportamiento de los proveedores. Google integra desde marzo de 2025 componentes de LLM directamente en los resultados de búsqueda con sus AI Overviews, muestra respuestas generadas por IA por encima de los resultados clásicos y experimenta con interfaces basadas en diálogo. Bing ha dado tempranamente un paso similar con la integración de tecnología GPT en «Bing Chat» y con ello ha puesto presión sobre Google. También startups como Perplexity.ai apuestan completamente por una experiencia de búsqueda asistida por LLM que incluye fuentes, pero se transmite principalmente a través del lenguaje.
Relevancia de la búsqueda tradicional
Al mismo tiempo, los motores de búsqueda clásicos siguen siendo relevantes, especialmente en áreas donde el control de fuentes, la actualidad y la transparencia son decisivos. Los LLM generan respuestas fluidas, pero no siempre proporcionan pruebas verificables o contenidos actuales. Precisamente en temas de actualidad, investigaciones complejas o informaciones legalmente vinculantes, la búsqueda mediante fuentes enlazadas sigue siendo indispensable.
A largo plazo se perfile un modelo híbrido: motores de búsqueda y LLM crecen juntos. El usuario recibe respuestas generadas por IA con indicaciones de fuentes, pero al mismo tiempo puede investigar más profundamente, contextualizar o verificar. Este desarrollo no es un desplazamiento, sino una reorientación del proceso de búsqueda: del modelo de clic a la estructura de diálogo, de la lista de URL a la respuesta de igual a igual.
Implicaciones para SEO
Para el SEO esto significa: los contenidos no solo deben ser legibles por máquinas, sino también «comprensibles para modelos». Estructura, claridad, autoridad y contexto ganan adicionalmente en importancia. Al mismo tiempo, los SEO deben prepararse para generar en el futuro significativamente menos alcance, ya que en muchas respuestas de IA a preguntas con una sola respuesta correcta ya no son necesarios clics. Pero esto no significa que no haya más clics a través del SEO.
Prueba SISTRIX gratis
- Cuenta de prueba gratuita durante 14 días
- Sin compromiso. No necesitas cancelarla.
- Onboarding personalizado con nuestros expertos.