
Una nueva propuesta está generando debate: con el archivo llms.txt, los SEO podrían, por primera vez, indicar de forma dirigida qué contenidos deberían ser procesados por sistemas de IA como ChatGPT o Gemini. En este artículo analizamos qué puede hacer este archivo, qué oportunidades y riesgos presenta y por qué, hoy por hoy, solo merece la pena para unos pocos proyectos.
¿Qué es el archivo llms.txt?
El llms.txt es una propuesta de nuevo estándar de interacción entre sitios web y sistemas de IA. Está pensado específicamente para los llamados Large Language Models (LLM), es decir, grandes modelos de lenguaje como ChatGPT, Claude o Gemini, que analizan y procesan contenidos procedentes de fuentes web accesibles públicamente.
Técnicamente, se trata de un archivo de texto sencillo en formato Markdown que se aloja en el directorio raíz (root) de un sitio web. Su objetivo es dirigir de forma explícita a los bots de IA hacia determinados contenidos, de manera similar a lo que hace un sitemap para los motores de búsqueda clásicos. La idea es ayudar a los LLM a identificar más rápido los contenidos relevantes y de alta calidad, y a utilizarlos de forma más eficiente.
A diferencia del robots.txt, que regula el acceso, y del sitemap.xml, que muestra la estructura completa del sitio, el llms.txt se centra en el contenido. Permite a los SEO especificar exactamente qué páginas son especialmente relevantes para los LLM (por ejemplo, guías, FAQ o artículos de asesoramiento clave).
Visibilidad en chatbots: los límites del llms.txt
La idea detrás del archivo llms.txt es comprensible: permitir a los SEO controlar qué contenidos deberían ser procesados por modelos como ChatGPT o Gemini. Sin embargo, en la práctica, su impacto es actualmente muy limitado, ya que los grandes proveedores no lo soportan activamente.
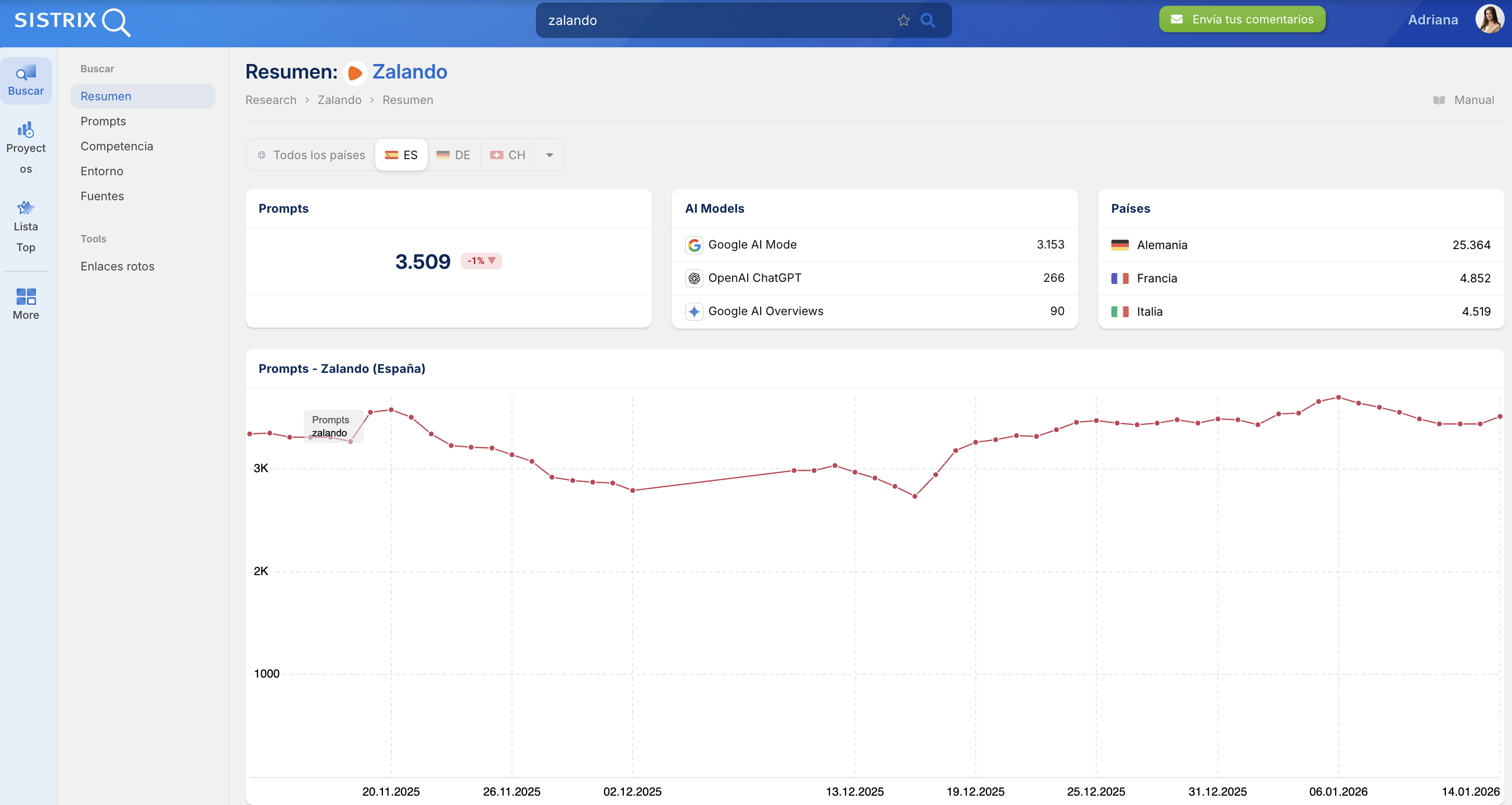
Quien quiera saber dónde aparece realmente una marca en las respuestas de los chatbots de IA necesita datos fiables, no simples indicaciones técnicas que pueden o no ser tenidas en cuenta.
Ejemplo de análisis de entidades con SISTRIX
Aquí es donde entra en juego la nueva beta de SISTRIX para el análisis de chatbots. A partir de diez millones de prompts cuidadosamente seleccionados, SISTRIX analiza:
- Para qué preguntas se citan dominios concretos
- Con qué frecuencia aparecen las marcas
- Qué contenidos son realmente procesados por los modelos de IA
De este modo, por primera vez es posible entender de forma sistemática cuánta visibilidad real tiene una marca en los sistemas de IA.
Quien quiera mantener su visibilidad deberá trabajar no solo en estrategias SEO operativas, sino sobre todo en análisis. Prueba SISTRIX gratis durante 14 días y descubre qué tan visible es tu marca en sistemas de búsqueda generativos.
¿Quién está detrás del archivo llms.txt?
El impulsor del archivo llms.txt es Jeremy Howard, cofundador del laboratorio de investigación en IA Fast.ai y de la empresa Answer.ai.
La primera publicación data del 3 de septiembre de 2024. En Answer.ai y GitHub, Howard presentó el archivo como una posible solución para proporcionar a los LLM contenidos web de alta calidad de forma más dirigida.
La estructura se basa en Markdown: títulos claros, una sección descriptiva y una lista de URL que deberían ser procesadas de forma preferente por los LLM. La idea es crear un índice transparente y fácil de mantener para los bots de IA.
Ejemplo de un archivo llms.txt
# llms.txt – Version 1.0
## Descripción
ejemplo.es ofrece recursos SEO para principiantes y expertos.
## Reference-Content:
- https://www.ejemplo.es/bases-seo
- https://www.ejemplo.es/guia/herramientas-seo-2026
- https://www.ejemplo.es/faq/preguntas-seo
## Sitemap:
- https://www.ejemplo.es/sitemap.xml
## Directivas:
User-agent: *
AI-Crawling: Allow
AI-Training: Allow
AI-Summarization: Allow
AI-Generation: AllowRelevancia práctica para el SEO y la LLMO
El debate sobre el llms.txt está directamente relacionado con la LLMO (Large Language Model Optimization), es decir, la optimización de contenidos para sistemas de respuesta basados en IA.
Cada vez más usuarios obtienen información no a través de las SERP tradicionales, sino mediante respuestas generadas directamente por modelos de lenguaje, por ejemplo en las AI Overviews de Google o en ChatGPT. Quien quiera ser visible en estos entornos debe asegurarse de que sus contenidos sean:
- Estructurados
- Claros
- Citables
- Fácilmente rastreables
El llms.txt pretende apoyar este proceso ofreciendo a los LLM una lista explícita de contenidos “recomendados” por el propio gestor del sitio.
En teoría, los LLM podrían así:
- Acceder más rápido a contenidos relevantes
- Gestionar mejor ventanas de contexto limitadas
- Extraer información de alta calidad de forma más precisa
- Dar más protagonismo al propietario del sitio en la generación de respuestas
Además, existe un posible beneficio técnico: ofrecer versiones Markdown “ligeras” de los contenidos puede reducir carga de servidor y actuar como una especie de API ligera para texto.
Argumentos a favor de su uso
Aunque el llms.txt es todavía una propuesta experimental, existen algunos motivos para plantearse su implementación:
- Acceso directo a los mejores contenidos: los LLM encuentran antes URLs clave sin atravesar menús o elementos irrelevantes.
- Bajo esfuerzo técnico: es fácil de crear y mantener, sin cambios profundos en CMS o arquitectura SEO.
- Cierto control sobre la representación en IA: se puede evitar destacar contenidos obsoletos.
- Ventajas técnicas con contenidos “ligeros”: archivos Markdown sin layout reducen ancho de banda y mejoran comprensión.
- Posicionamiento temprano ante posibles estándares futuros: robots.txt o schema.org también empezaron así.
Críticas y contraargumentos
Frente a estos puntos, existen críticas de peso:
- Difusión mínima: menos del 0,005 % de los sitios lo utiliza actualmente.
- Sin apoyo de los grandes proveedores: Google ha aclarado que no lo usa. John Mueller lo ha comparado con la antigua meta-keywords, ignorada por abuso SEO.
- Riesgo de abuso y cloaking: se podrían enlazar contenidos distintos a los visibles para usuarios o buscadores.
- Sin beneficios SEO demostrables: no hay pruebas de mejora en rankings ni visibilidad.
- Costes de mantenimiento sin retorno claro, especialmente en sitios grandes.
¿Qué dicen Google, OpenAI y otros actores?
- Google rechaza el llms.txt por considerarlo poco específico y recomienda marcarlo como noindex.
- OpenAI no se ha pronunciado oficialmente, aunque aparecen rastreos de OAI-SearchBot en logs.
- Yoast ha adoptado la propuesta y permite generar el archivo automáticamente en su plugin.
- Algunos proveedores pequeños están experimentando, pero aún no existe un ecosistema real.
Entonces, ¿debo implementar llms.txt?
Depende mucho del tipo de sitio:
- SEO experimentales y proyectos centrados en IA: puede ser interesante hacer pruebas controladas y analizar logs.
- Webs corporativas clásicas: no hay beneficio real hoy; mejor invertir en calidad de contenido, Core Web Vitals y datos estructurados.
- Plataformas editoriales grandes: puede servir como capa adicional para destacar contenidos muy citables, siempre que ya estén bien estructurados.
Conclusión
El archivo llms.txt es una propuesta técnicamente interesante, pero prácticamente irrelevante a día de hoy. Su origen en el entorno de empresas de IA muestra que, como ocurre a menudo con la inteligencia artificial, existen también intereses estratégicos y económicos detrás.
No hay urgencia en actuar. Quien quiera experimentar puede hacerlo; quien prefiera esperar a que surjan estándares consolidados no se equivoca y probablemente ahorre recursos.
Lo que sigue siendo clave —para buscadores y para LLM— es lo de siempre: contenidos bien estructurados, citables, una base técnica limpia y una navegación clara. Ese es el verdadero takeaway.
Prueba SISTRIX gratis
- Cuenta de prueba gratuita durante 14 días
- Sin compromiso. No necesitas cancelarla.
- Onboarding personalizado con nuestros expertos.