
Al igual que muchos otros SEOs, a principios de agosto me preguntaba si el error de rankings de Google (error de indexación) podría ser el signo de una nueva actualización o si estos cambios en los rankings proporcionarían algunas ideas o pistas sobre cómo funciona la optimización.
Descubre cómo SISTRIX puede ayudarte a mejorar tu posicionamiento en buscadores. Accede gratis durante 14 días a todos los datos y funciones, sin compromiso y sin costes ocultos: Probar SISTRIX gratis
Probablemente ya lo habrás oído pero para aquellos que no seguís paso a paso todo lo que ocurre con Google, aquí tenéis un resumen:
A principios de agosto aumentaron masivamente las fluctuaciones de los resultados de búsqueda de Google, en todo el mundo y en todos los idiomas. En los foros de Webmasters y en los habituales foros de Black Hat hubo inmediatamente especulaciones sobre el despliegue de una actualización masiva sin previo aviso. Las fluctuaciones y los cambios en los resultados de búsqueda fueron tan grandes que varios de los principales portales de SEO en EE.UU. informaron de la mayor actualización de la historia.
De hecho, todas las herramientas de SEO y las comprobaciones de rankings fueron repentinamente «golpeadas» con cambios masivos en los resultados de búsqueda de Google. Los resultados de la búsqueda no solo cambiaron sino que se pusieron del revés, a veces incluso con resultados absurdos que ocupaban las primeras posiciones.
Puedes ver los efectos del bug claramente en el índice de visibilidad diario:
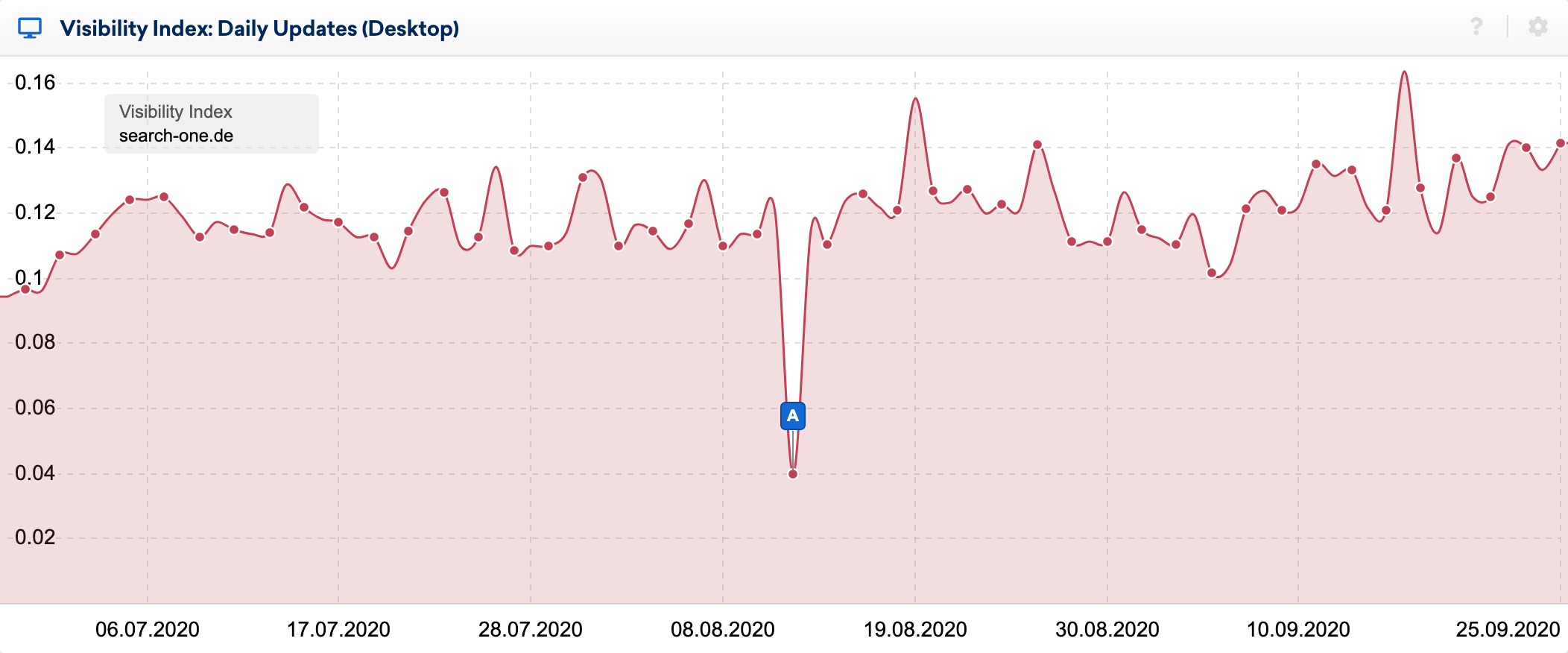
Usando la función de comparación de SERPs en SISTRIX: eché un vistazo más de cerca a los cambios dentro de las 20 primeras posiciones (versión traducida a español) de algunas palabras clave, cuyos rankings he estado observando durante muchos años. He hecho docenas de análisis de sitios web posicionados para estas palabras clave y por lo general sé relativamente bien por qué una URL posiciona donde lo hace.
Si miras la comparación de los SERPs para la palabra clave «google optimisation» en el momento en cuestión, verás que todo el top 20, con la excepción de una URL, cambió completamente. Lo que antes estaba en el primer lugar bajó al octavo lugar, con el resto de las URLs saliendo de la nada, es decir, desde fuera de las 20 primeras posiciones a los primeros puestos.
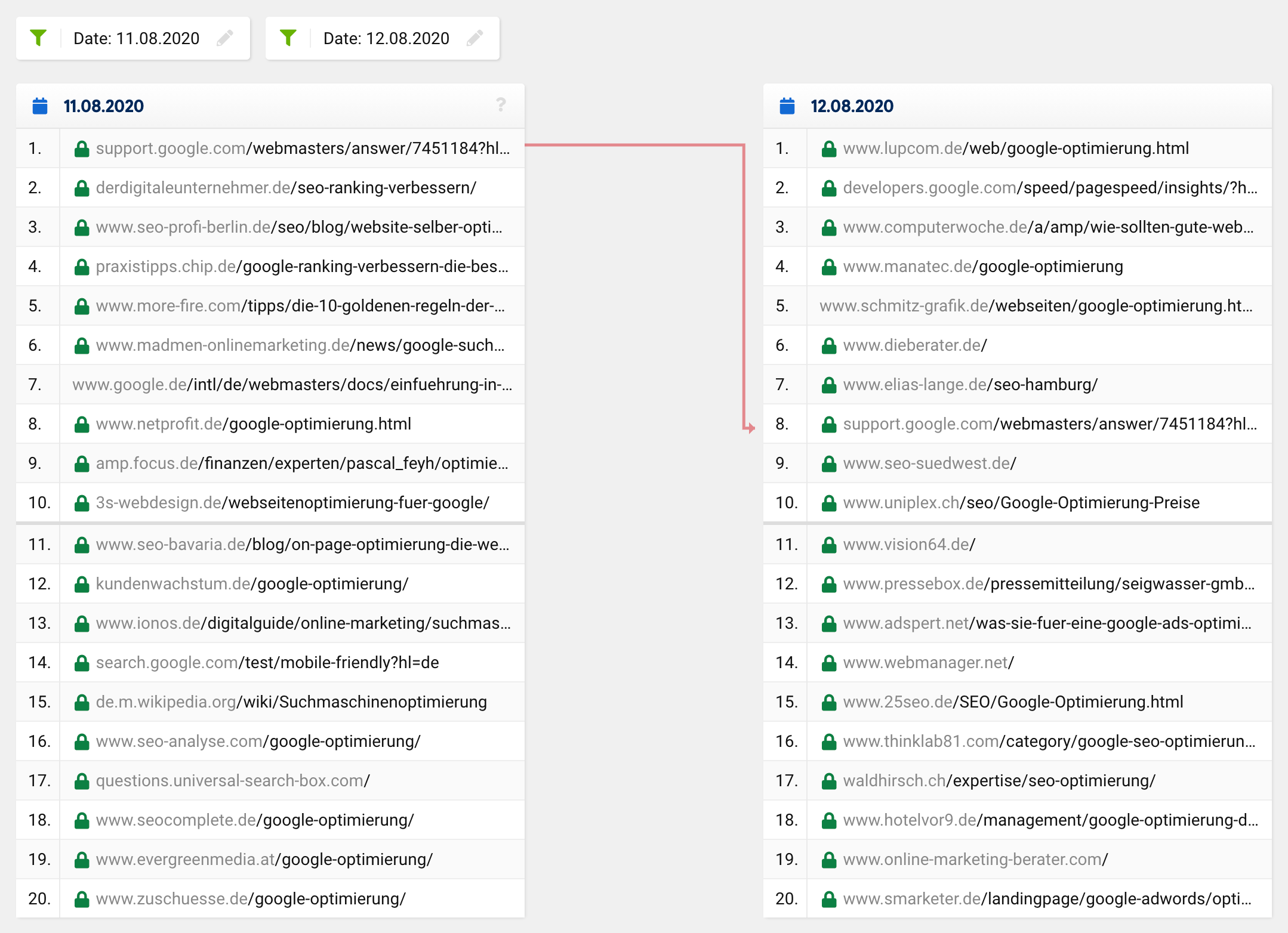
Una actualización normal o un cambio de ranking habitual normalmente se vería más como esto:

Muchas URLs permanecen igual mientras que otras URLs se mueven hacia arriba y otras hacia abajo. Por supuesto, a veces una URL desaparece de los 20 primeros puestos o se mueve hacia arriba. Sin embargo, es increíblemente raro que de los 20 resultados solo quede una en el «nuevo» top 20 – esto ocurrió en general, no solo para una palabra clave concreta.
Dados estos cambios de gran alcance similares a las notorias actualizaciones fantasma, se esperaría ver un ajuste en la supuesta intención del usuario de una consulta de búsqueda, lo que llevaría a cambios fundamentales en la composición de los 20 principales resultados para algunas palabras clave. En tal caso, sin embargo, los resultados de la búsqueda mejorarían, es decir, se harían más relevantes y significativos, lo que obviamente no fue lo que ocurrió con este fallo.
La gran mayoría de los SEOs se sorprendieron por los resultados de búsqueda obviamente absurdos y asumieron relativamente rápido que había un error – o al menos esperaban que fuera solo un problema temporal. Me sentí igual, ya que algunos de mis sitios web perdieron completamente sus rankings más importantes ¡en tan solo unas pocas horas!
Una desagradable sorpresa: ¡Fue solo un error!
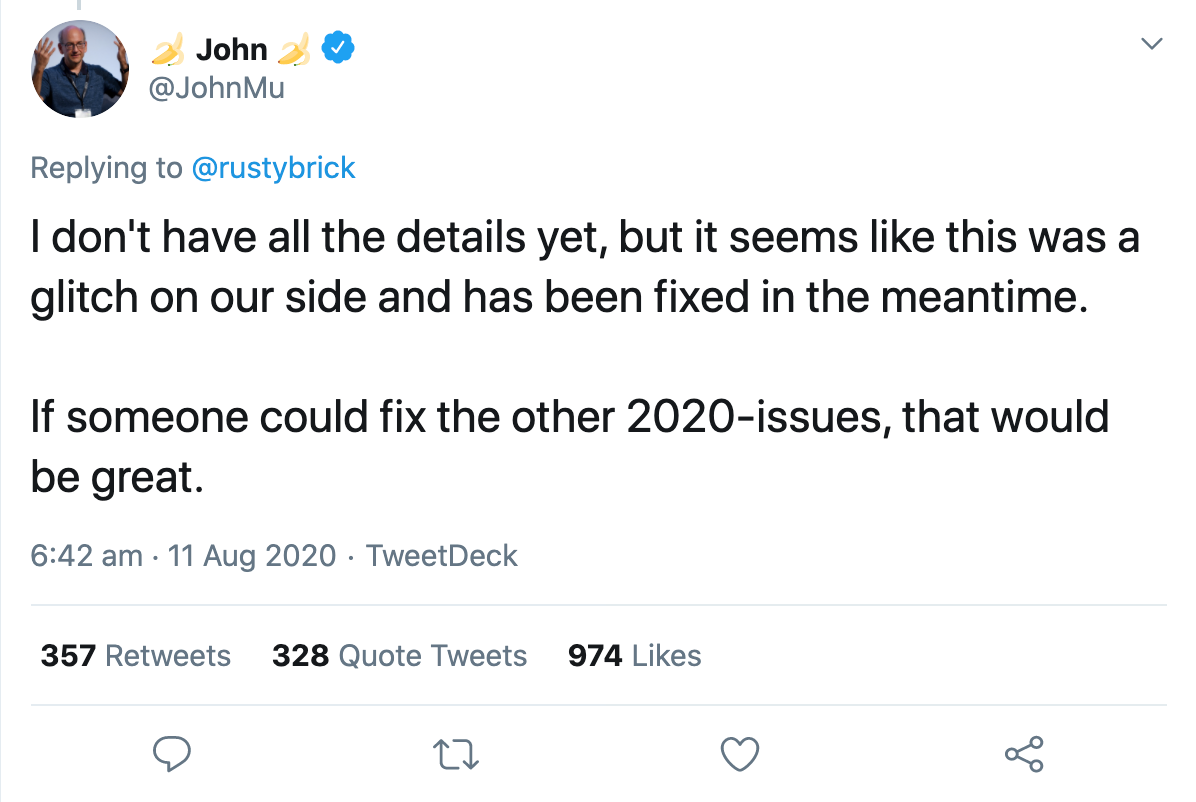
Esa misma noche, un portavoz de Google confirmó que era un error que estaban arreglando. En pocas horas, todo volvió a la normalidad. John Müller confirmó a través de Twitter que el error había sido arreglado, pero que no tenía todos los detalles aún:
Solo un día después, la cuenta oficial de Google Webmasters confirmó que los resultados de búsqueda se habían visto afectados por un aparente problema con el sistema de indexación.
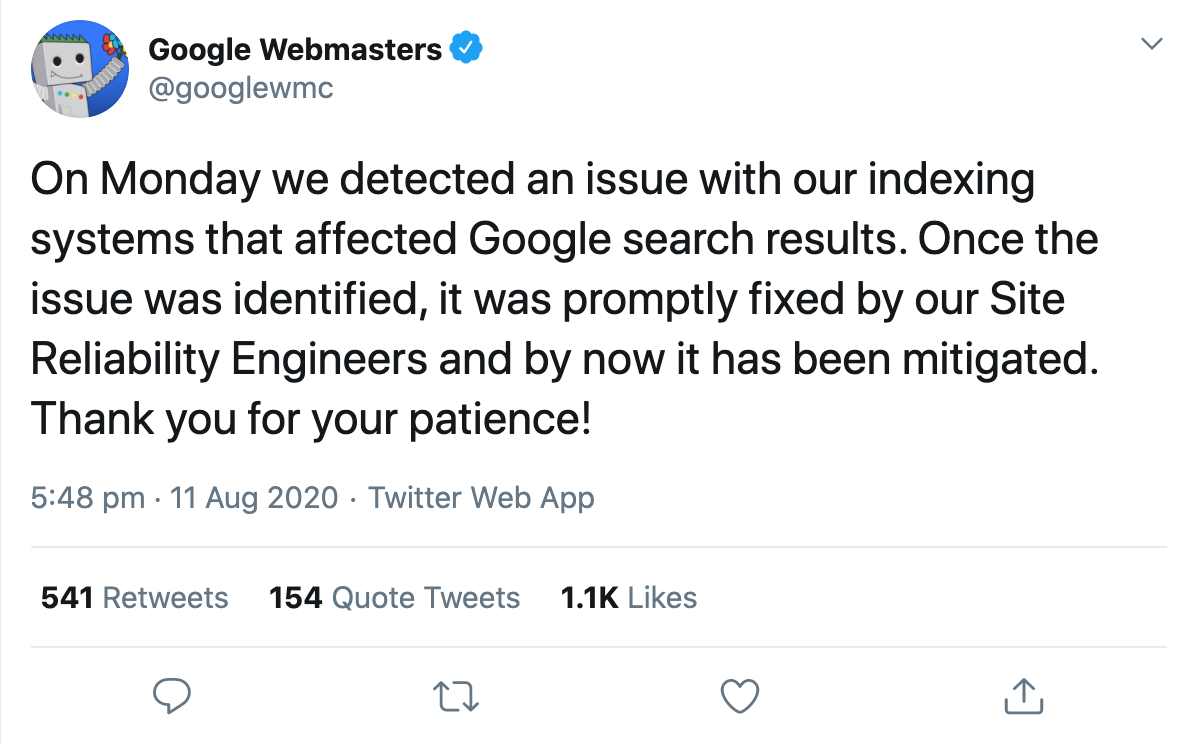
Y aquí es donde la gente empezó a especular sobre lo que podría haber pasado exactamente.
Gary Illyes trató de aclarar un poco más las cosas describiendo lo que el sistema de indexación, Google Caffeine, realmente hace. De acuerdo con su tweet, ingiere «fetchlogs», representa y convierte los datos obtenidos, extrae enlaces, metadatos y datos estructurados, extrae y calcula algunas señales sin nombre, programa nuevos rastreos y construye el índice que finalmente se sirve. Para facilitar la comprensión, dio algunos ejemplos de lo que podría salir mal y que se reflejaría en los resultados de búsqueda modificados:
“If scheduling the crawls goes awry, crawling may slow down. If rendering goes wrong, Google may misunderstand the pages. If index building goes bad, ranking and serving may be affected.”
«Si la programación de los rastreos sale mal, los rastreos pueden ir más despacio. Si la renderización no es correcta, Google puede malinterpretar las páginas. Si la creación del índice sale mal, la clasificación y la publicación pueden verse afectadas».
A continuación, destacó lo compleja que es la búsqueda y que miles de sistemas interconectados deben trabajar juntos de forma impecable para ofrecer resultados relevantes a los usuarios. Si se arroja un grano de arena en la maquinaria, el resultado sería una interrupción como la de ayer.
Cuando un usuario de Twitter le preguntó, especificó que aparentemente había habido un error en la construcción del propio índice:
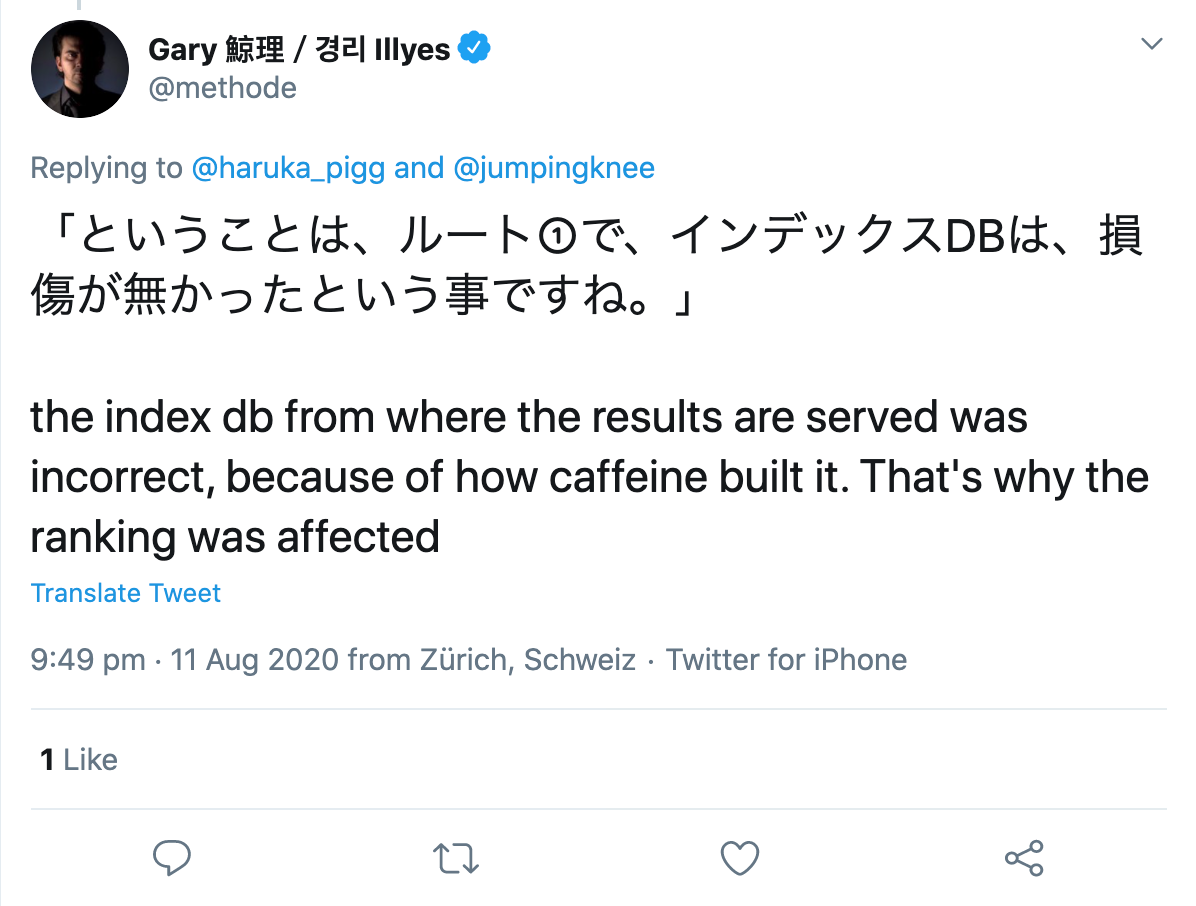
Entonces, ¿dónde está el problema de todo esto?
El error en sí mismo no me molestó, ya que era solo cuestión de horas que Google arreglara el problema. Sin embargo, algunos comentarios y publicaciones posteriores sobre esto sí me hicieron enfadar bastante.
Aunque Google había revelado el problema con relativa transparencia, algunos SEO trataron de darle sentido al error por las buenas o por las malas y comenzaron a examinar los cambios para buscar patrones. Un empleado de una conocida agencia americana de SEO, a quien no quiero exponer ahora, comenzó a analizar los datos de Google Analytics de cada cliente actual y anterior e intentó sacar conclusiones sobre el motivo de los cambios de ranking.
Considero que esto es cruzar la línea por varias razones, pero profundizaremos en el tema después.
¿Qué averiguaron los empleados sobre el fallo?
En el caso de las actualizaciones habituales de Google, todas las subpáginas de un dominio suelen verse afectadas por el cambio, ya sea positivo o negativo. Este no era el caso con el fallo actual, porque mientras algunas subpáginas de un mismo dominio sufrieron pérdidas masivas, otras se beneficiaron y algunas apenas cambiaron, sí es que lo hicieron.
Por lo tanto, la primera idea fue que no parecía una típica actualización de Google. Hasta aquí, todo bien.
Ahora se vuelve algo atrevido:
“Many pages that went higher up the rankings contained medical information that contradicted the scientific consensus. For clarification, reference is made here to the Google Quality Rater Guidelines which state that when determining the E-A-T of a page on scientific topics, it should be created by people or organisations with expertise in the respective field and should reflect the established consensus of science, where one exists.”
«Muchas de las páginas que subieron en rankings contenían información médica que contradecía el consenso científico. Para clarificar, se hace referencia aquí a las Directrices Google Quality Rater Guidelines que establecen que cuando se determina la E-A-T de una página sobre temas científicos, debe ser creada por personas u organizaciones con experiencia en el campo específico y debe reflejar el consenso establecido de la ciencia, cuando exista».
Esta afirmación está «probada» por la observación, ya que unos pocos artículos médicos, que obviamente contradicen a la ciencia y también tienen enlaces malos o antinaturales, de repente se posicionaron mucho mejor que antes después del fallo.
Su teoría es que las páginas que deberían ser devaluadas por problemas de calidad en realidad se posicionaron bien. Por ejemplo, las páginas pirateadas, las páginas con enlaces antinaturales o las páginas con afirmaciones que se desvían del consenso científico general se habrían catapultado a las primeras posiciones.
De esto, deduzco lo siguiente:
Si el ranking de una página mejora, esto podría ser un motivo de regocijo, o tal vez solo fue una prueba para una futura actualización que salió mal. O podría ser un indicio de un problema de calidad en el sitio web que limitó el ranking de la página, pero podría no haber jugado un papel en el momento del fallo.
Por otro lado, si una página se hubiera movido hacia abajo en los rankings podría significar que fue superada por páginas inferiores o Spam, que una vez más están actualmente degradadas por los algoritmos de Google.
¡Uff! ¿En serio? ¡¿De qué sirve este punto de vista para mi trabajo diario de SEO?!
¿Por qué no realizar este tipo de análisis?
Aparte del hecho de que todavía tienen acceso y utilizan los datos de Google Analytics de los antiguos clientes, veo un problema mucho más grande aquí con el enfoque del empleado:
El problema es que si buscas patrones sin una hipótesis, siempre los encontrarás, pero esto no tiene nada que ver con la ciencia. Siempre hay patrones, a veces aleatorios, a veces causados por uno o más factores. No puedes buscar patrones primero y luego diseñar una teoría para explicar lo que observas. No es así como funciona el conocimiento.
Me gustaría ver más métodos científicos en el SEO, por ejemplo cuando se trata de hacer hipótesis y luego probarlas.
¿Qué es una hipótesis y cómo se formula correctamente?
Una hipótesis es una suposición razonable que se hace al principio de un estudio empírico. Esta hipótesis se analiza mediante métodos cualitativos o cuantitativos y luego se confirma o se refuta.
Cuando se hace una hipótesis, se asume una correlación o ninguna correlación entre dos variables. Una variable independiente es la causa, la variable dependiente es el posible efecto.
Hay esencialmente dos tipos de hipótesis: dirigidas y no dirigidas.
Con una hipótesis no dirigida, simplemente se asume que hay alguna correlación entre dos variables. Por ejemplo, el número de sitios web vinculados influye en la visibilidad de un dominio.
Con una hipótesis dirigida, por otra parte, se evalúa la presunta correlación. Por ejemplo: cuantos más enlaces tenga un artículo, mejor se posiciona.
Sin embargo, para hacer una hipótesis se deben considerar los siguientes criterios:
- Las dos variables utilizadas deben ser medibles.
- Las hipótesis deben formularse de forma objetiva y concisa.
- Si se formulan varias hipótesis, éstas no deben contradecirse entre sí.
- Y: Las hipótesis científicas deben poder ser refutadas.
Dado que la mayoría de las suposiciones en el campo del SEO no pueden ser rebatidas por un experimento, no hay evidencia para hablar de una perspectiva científica. De igual modo, no se deben analizar los resultados de ninguna de las consultas de búsqueda para sacar conclusiones sobre los factores de ranking utilizados.
El hecho de que la correlación no es igual a la causalidad se ha aceptado afortunadamente en los últimos años. Los estudios sobre los factores de ranking de cualquier proveedor de herramientas ya no son tomados en serio por ningún SEO experimentado hoy en día, lo que significa que cada vez se realizan y se publican menos.
Prueba SISTRIX gratis
- Cuenta de prueba gratuita durante 14 días
- Sin compromiso. No necesitas cancelarla.
- Onboarding personalizado con nuestros expertos.
