

En este artículo vamos a intentar hacer un análisis pormenorizado y paso a paso de las palabras clave y URLs posicionadas de un proyecto o de un clúster temático, para verlo en detalle y establecer el punto de partida de un posible plan de acción (de mejoras SEO).
- Palabras clave posicionadas en total o de un clúster concreto
- Usando filtros con regex (expresiones regulares)
- Usando elegir columnas
- Preparando los datos: calcular campos adicionales con fórmulas
- Tipo de palabra: marca vs genérica y diferenciar short, mid o long tail
- Página de Google correspondiente a la posición
- Nivel de visibilidad en base a la posición
- Clasificación de URL: longitud, parámetros, niveles, formatos, directorios...
- Nivel de volumen de búsqueda, nivel de competencia y nivel de CPC: alto, medio, bajo
- Intención de búsqueda predominante
- Trabajando y visualizando los datos: tablas dinámicas
- Distribución de rankings: por tipo de palabra
- Distribución de rankings: por nivel de visibilidad y por secciones
- Distribución de rankings: por volumen/ competencia
- Distribución de rankings: por intención de búsqueda
- Conclusiones y aprendizajes
Palabras clave posicionadas en total o de un clúster concreto
Normalmente podemos usar la opción de «Distribución de los rankings» para analizar un dominio, un subdominio, un directorio o incluso una URL, para identificar dónde se concentran los principales rankings (a nivel cuantitativo)
Vamos a tratar de focalizar este análisis yendo a un grupo o clúster concreto y descargando las palabras clave posicionadas.
Usando filtros con regex (expresiones regulares)
En nuestro tutorial de expresiones regulares puedes revisar muchos usos típicos en los que puedes usar regex para acotar, especificar o extraer grupos de palabras clave o URLs, con criterios especiales o múltiples.
Para este ejemplo, tan solo vamos a excluir todas las URLs informativas (del Path blog o diccionario), para llegar a las URLs posicionadas de páginas de servicios.
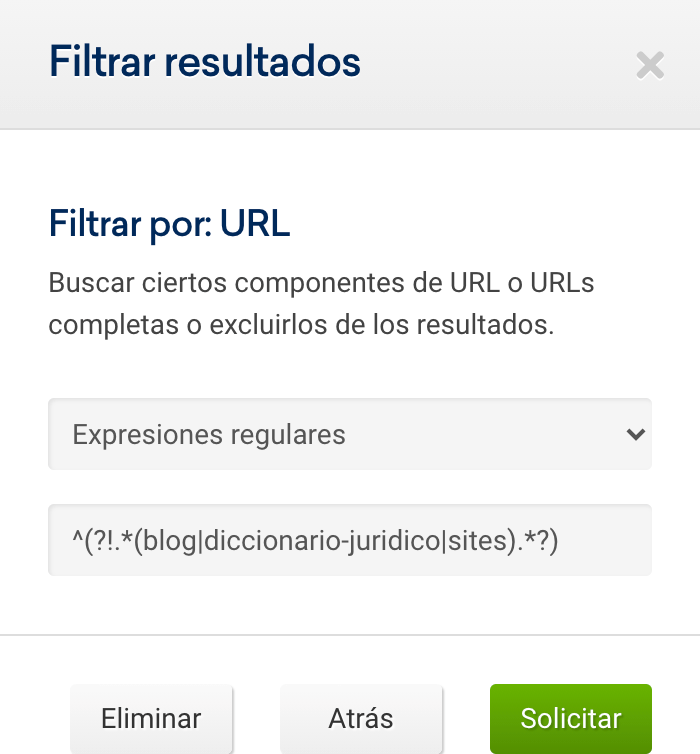
Después del filtrado, podremos descargar las palabras posicionadas totales, desde la interfaz
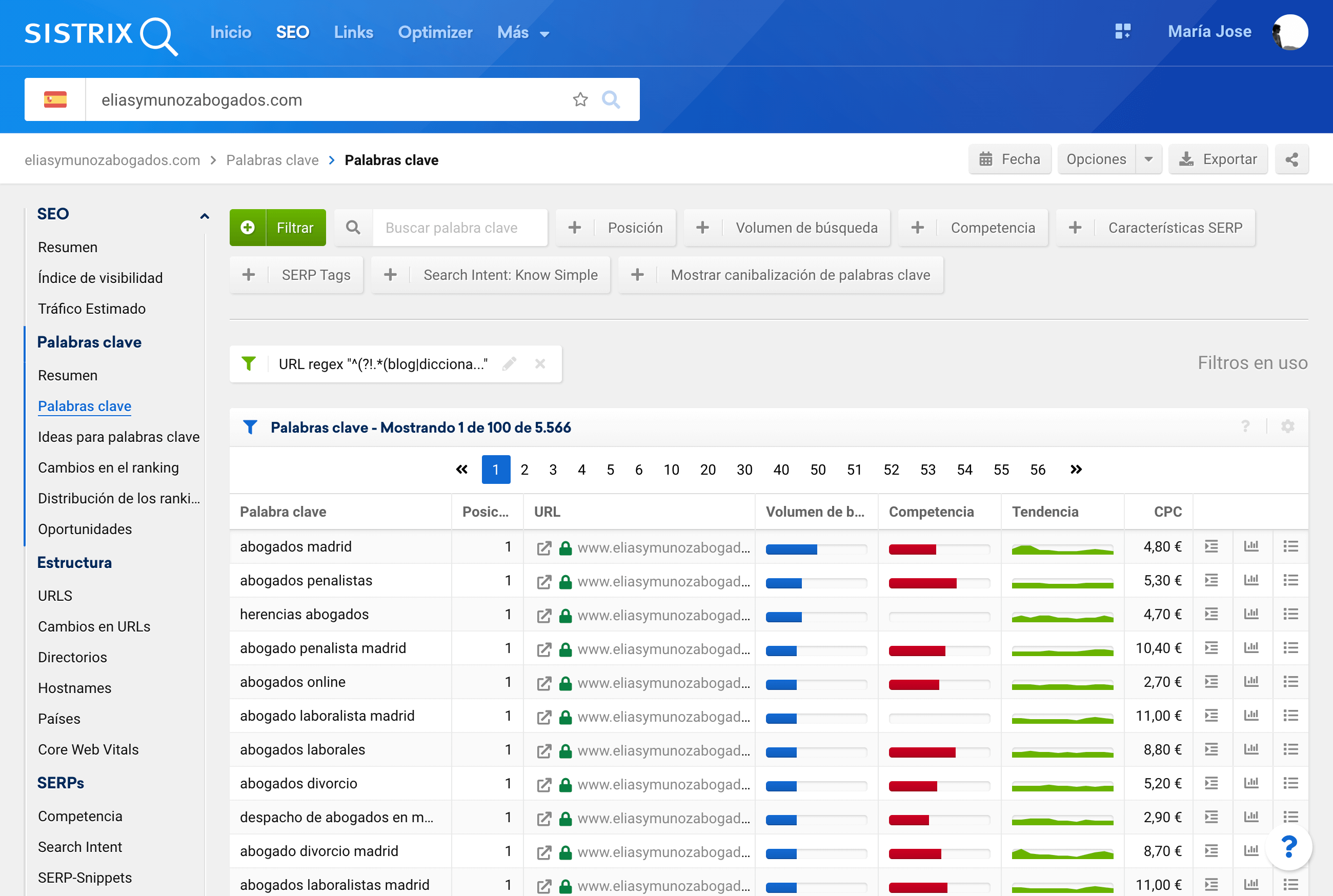
Usando elegir columnas
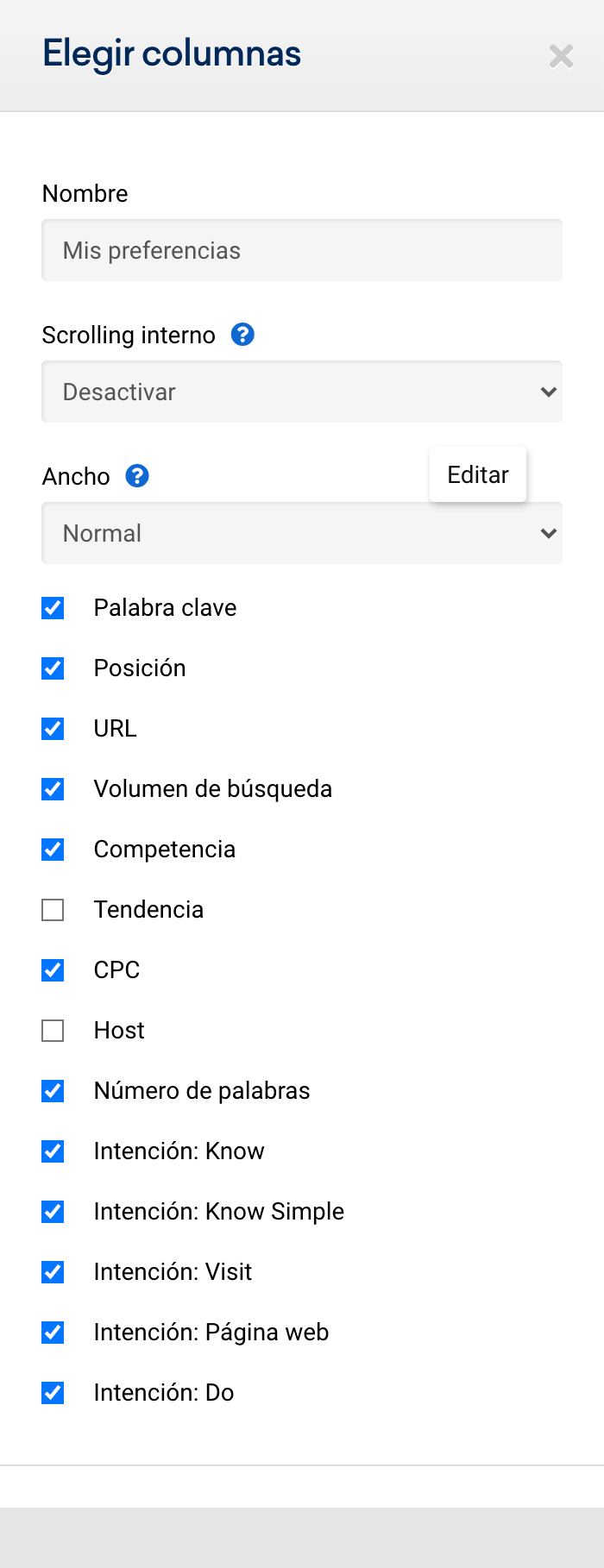
Pero antes de descargar vamos a hacer uso de una de las opciones más útiles para personalizar los datos y poder trabajarlos posteriormente: elegir columnas.
Lo que vamos a hacer es añadir a la tabla anterior datos también sobre intención de búsqueda y la longitud de la palabra clave.
Y ahora ya podemos descargar las palabras clave posicionadas del clúster elegido para trabajarlo en nuestra hoja de cálculo
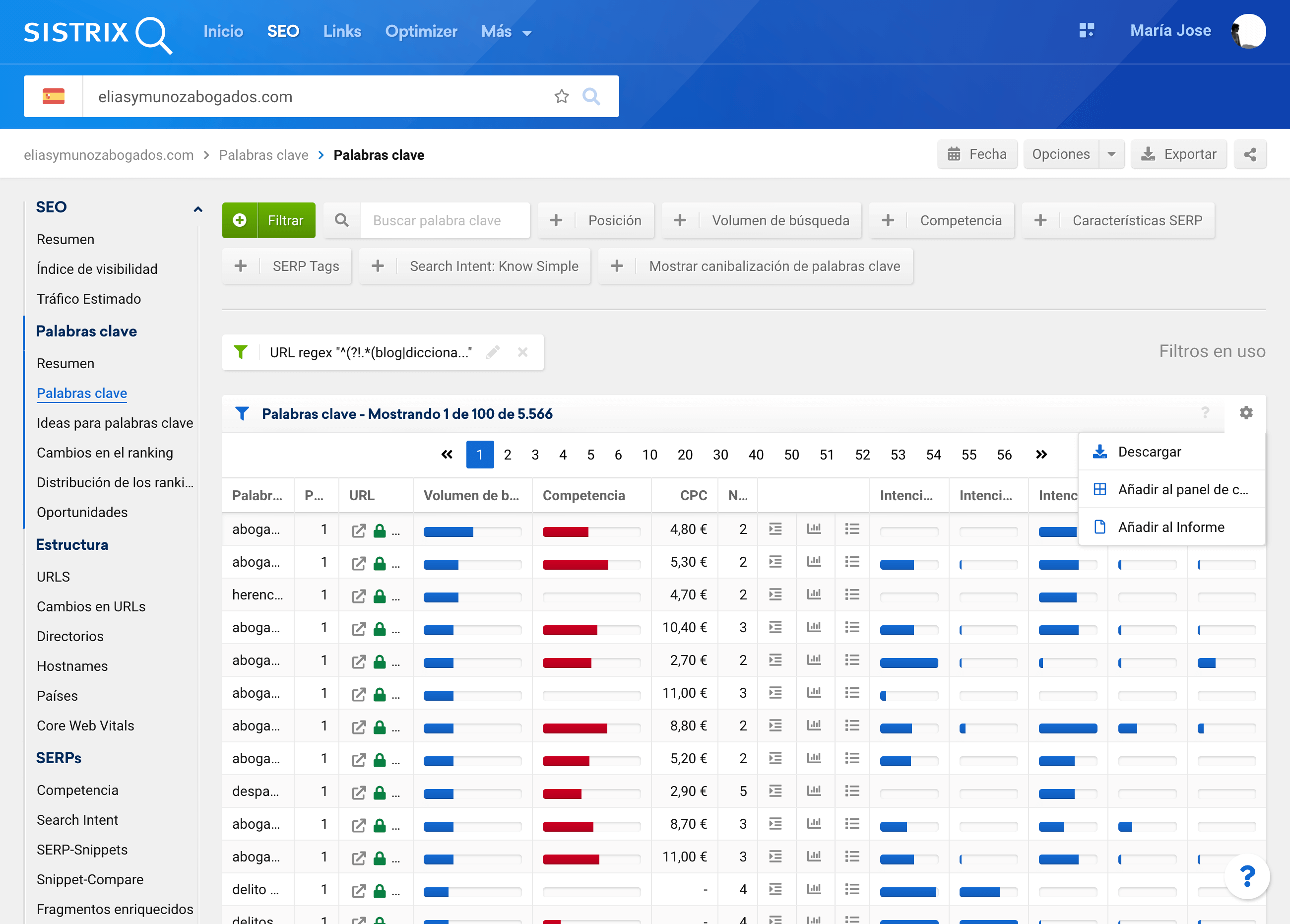
Preparando los datos: calcular campos adicionales con fórmulas
Cuando trabajamos con datos es imprescindible prepararlos antes de empezar a analizarlos. Debemos asegurarnos que hemos limpiado perfectamente los datos, que los hemos formateado de la mejor manera para su posterior tratamiento y que tenemos todos los campos que necesitamos para luego analizar.
Con la descarga efectuada, disponemos de los siguientes datos:
- Palabra clave
- Posición
- URL
- Número de palabras (de la cadena de búsqueda)
- Volumen de búsqueda
- Competencia
- CPC
- Intent: Know
- Intent: Know Simple
- Intent: Visit
- Intent: Página Web
- Intent: Do
¿Y qué campos vamos a calcular a partir de éstos para poder analizarlos después?
- Tipo: a partir de si la palabra es de marca o es genérica.
- Tipo de palabra: a partir del número de palabras o longitud
- Página Google: a partir de la posición, en qué página de Google se encuentra
- Nivel de Visibilidad: a partir de la posición si tiene o no buena visibilidad
- Store View y Path: a partir de la URL podemos sacar la carpeta de país e idioma y el path, si aplica
- Parámetros: a partir de la URL podemos sacar si tiene o no parámetros
- Nivel de Volumen: a partir del volumen podemos sacar si son altos o no
- Nivel de Competencia: a partir de la competencia podemos sacar si es alta o no
- Nivel de CPC: a partir del CPC podemos sacar si son palabras clave con una coste por clic elevado o no
- Intención predominante: a partir de las intenciones de búsqueda, podemos saber cuál es la mayor
Estas son las que yo propongo, pero en base a los datos que nos descargamos, los datos que le podáis unir, podréis calcular más campos propios que luego os ayuden a articular un análisis más profundo.
Tipo de palabra: marca vs genérica y diferenciar short, mid o long tail
Podemos clasificar la longitud de la cadena de búsqueda para inferir si la palabra es short tail, mid tail, long tail o long tail extremo. Este dato lo podéis ver desde la interfaz de SISTRIX, desde el resumen de palabras clave, para identificar qué tipo de palabras clave se posicionan en global

Para este post solo tendremos en cuenta la longitud, pero para vuestros análisis podéis calcular una métrica propia entre longitud y volumen de búsqueda, ya que no siempre se cumple que una cadena de búsqueda de 2 palabras, es mid tail.
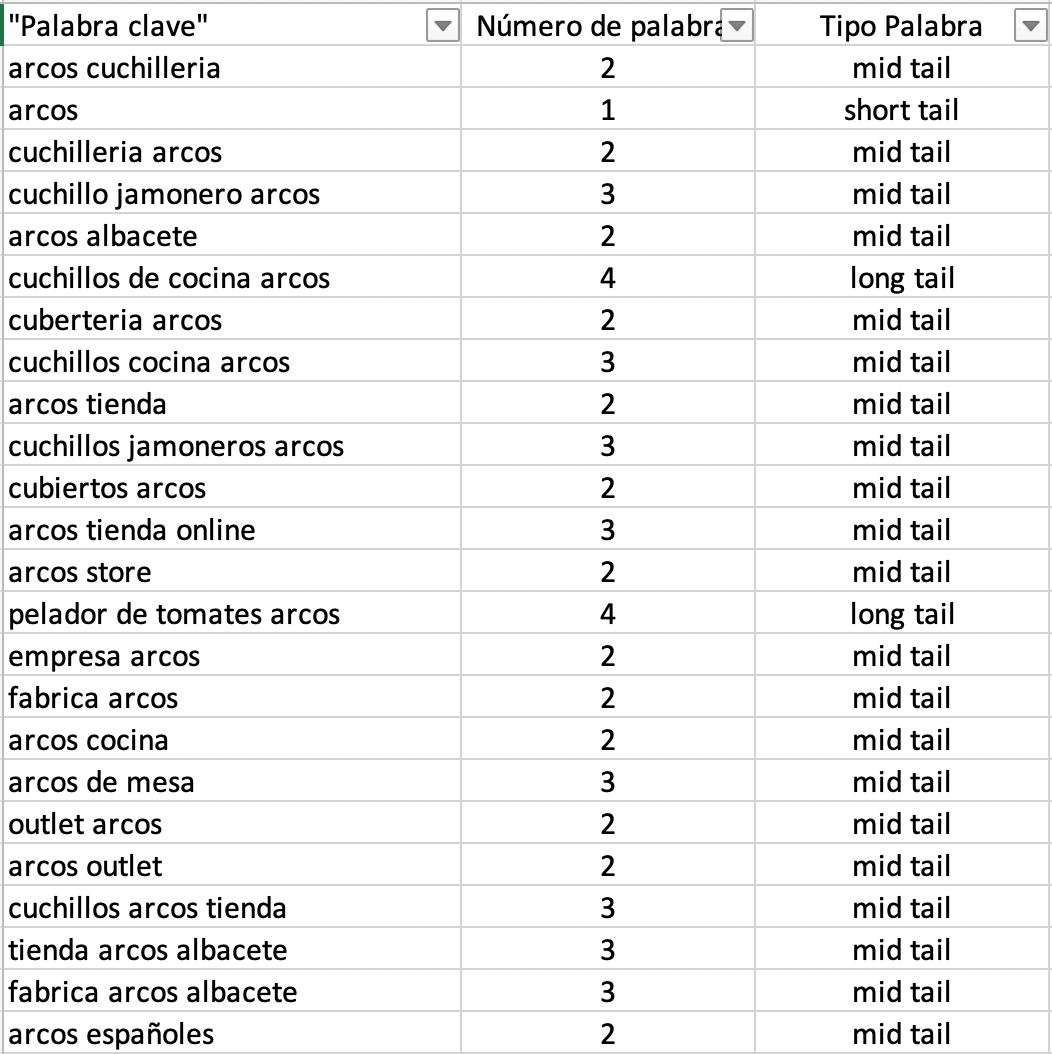
¿Cómo agilizarlo en Excel o Google Sheets?
=SI(Y(B2=1);"short tail";SI(Y(2<=B2;B2<=3);"mid tail";SI(Y(3<B2;B2<=5);"long tail";"long tail extremo")))Por otro lado, para diferenciar una palabra de marca de una genérica podemos hacerlo filtrando con contiene o no contiene o, usando una fórmula que lo extraiga automáticamente
¿Cómo agilizarlo en Excel o Google Sheets?
=SI(SI.ERROR(HALLAR("nike";C18);0)>0;"Brand";"No brand")Página de Google correspondiente a la posición
Otro aspecto interesante es obtener la página de Google a la que corresponde la posición para saber cuántas palabras y de qué tipo, se posicionan en la página 1, página 2, etc.
Ya sabéis que esto va de 10 en 10, de la posición 1 a la 10 es la página 1, de la 11 a la 20 es la página 2, etc.
Esto lo podéis obtener directamente en el apartado «Distribución de los rankings», pero lo que queremos hacer es profundizar en esa distribución, añadiendo más criterios
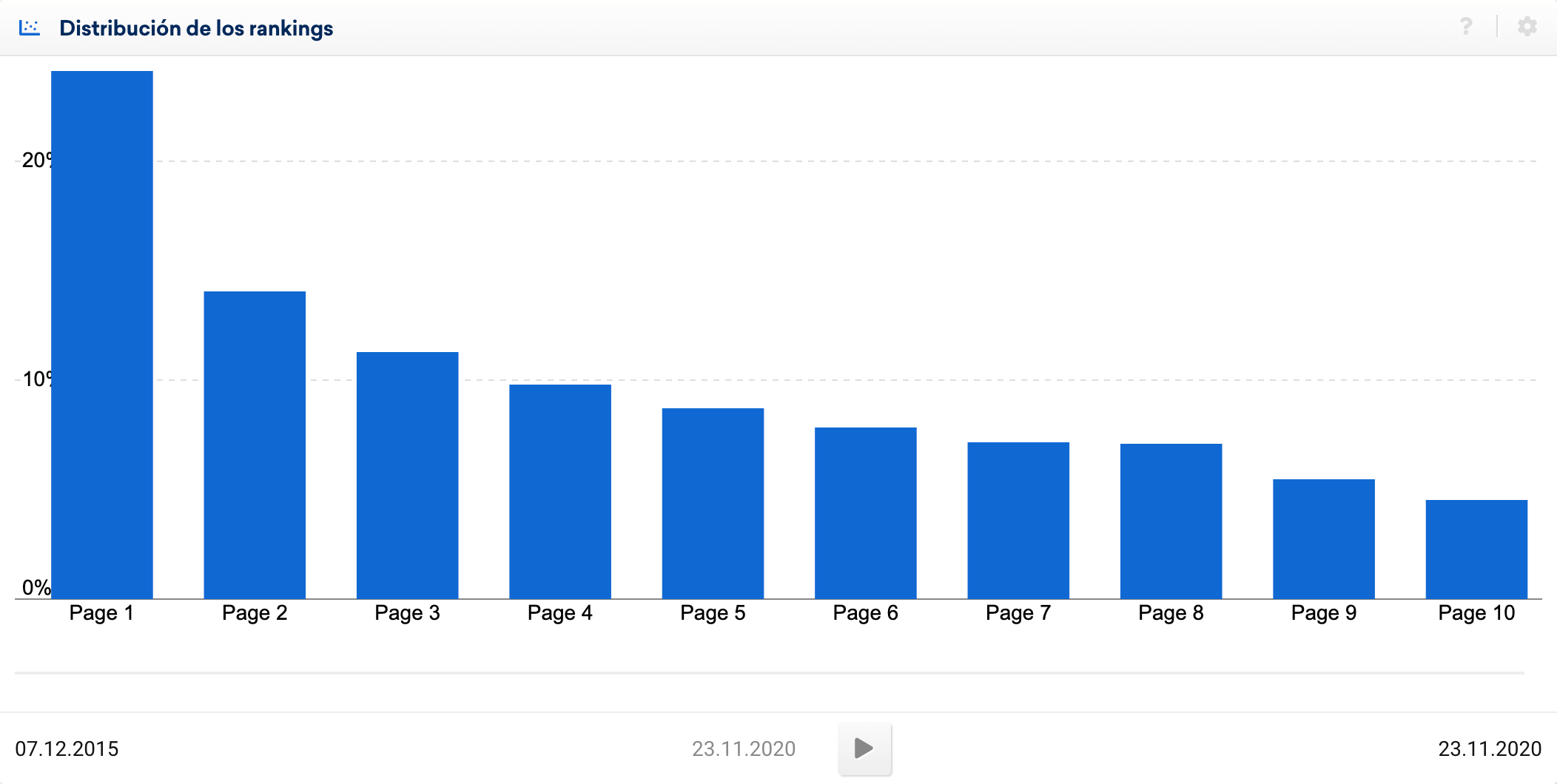
¿Cómo agilizarlo en Excel o Google Sheets?
=SI(Y(1<=D2;D2<=10);"página 1";SI(Y(11<D2;D2<=20);"página 2";SI(Y(20<D2;D2<=30);"página 3";SI(Y(30<D2;D2<=40);"página 4";SI(Y(40<D2;D2<=50);"página 5";SI(Y(50<D2;D2<=60);"página 6";SI(Y(60<D2;D2<=70);"página 7";SI(Y(70<D2;D2<=80);"página 8";SI(Y(80<D2;D2<=90);"página 9";"página 10")))))))))Nivel de visibilidad en base a la posición
También en base a la posición vamos a poner una escala de cómo de buena es dicha posición:
- Entre posición 1 y 5, diremos que es Muy Buena
- Entre posición 5 y 10, diremos que es Buena
- Entre posición 11 y 20, diremos que es Regular
- Entre posición 21 y 100, diremos que es Mala
¿Cómo agilizarlo en Excel o Google Sheets?
=SI(Y(0<D2;D2<=5);"muy buena";SI(Y(5<D2;D2<=10);"buena";SI(Y(10<D2;D2<=20);"regular";"mala")))Clasificación de URL: longitud, parámetros, niveles, formatos, directorios…
Estos campos son algo más optativos y dependerán en suma del tipo de proyecto que estemos analizando. Se pueden clasificar la longitud de las URLs, el número de niveles físicos de la URL, los formatos, etc.
Desde la herramienta lo podréis ver en la sección de «Estructura> URLs» para identificar ciertos patrones que captan rankings y que, quizás, no son URLs objetivo.
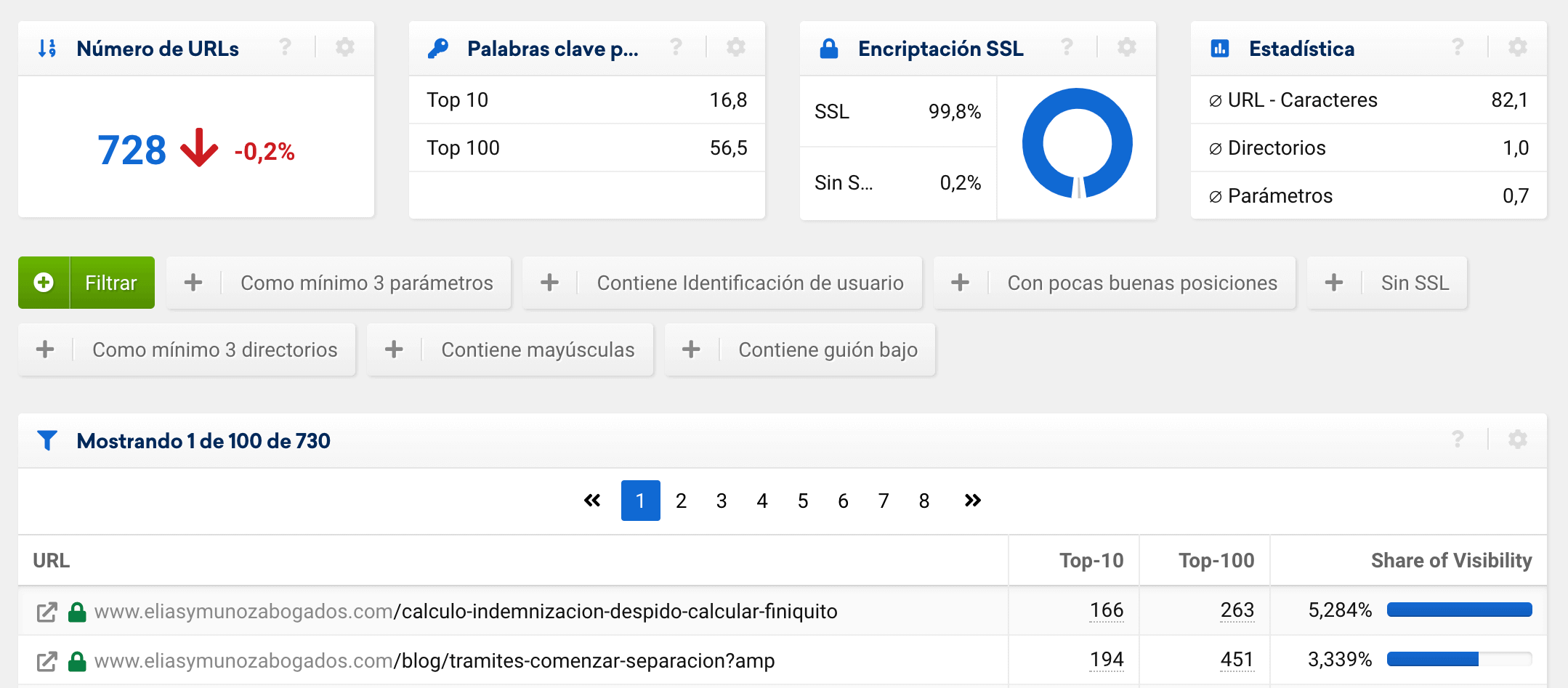
Por otro lado, otra posible agrupación para tener un dato por el que agrupar es el de directorios o secciones, que es fácil de extraer usando «datos en columnas», tanto en Excel como Sheets.
Nivel de volumen de búsqueda, nivel de competencia y nivel de CPC: alto, medio, bajo
En base al volumen, la competencia y el CPC vamos a poner una escala de cómo de bueno es el dato:
- Volumen: muy bajo, bajo, medio, alto y muy alto
=SI(Y(0<=O2;O2<=15);"muy baja";SI(Y(15<O2;O2<=100);"baja";SI(Y(100<O2;O2<=700);"media";SI(Y(700<O2;O2<=5000);"alta";"muy alta"))))- Competencia: baja, media, alta y muy alta
=SI(Y(0<=Q2;Q2<=10);"baja";SI(Y(10<Q2;Q2<=30);"media";SI(Y(30<Q2;Q2<=60);"alta";"muy alta")))- CPC: bajo, medio, alto
=SI(Y(0<S2;S2<=0,5);»bajo»;SI(Y(0,5<S2;S2<=1);»medio»;»alto»))
Intención de búsqueda predominante
Con la funcionalidad de detección de Search Intent de cada palabra clave es fácil identificar qué intención está detrás de cada búsqueda, a nivel numérico.
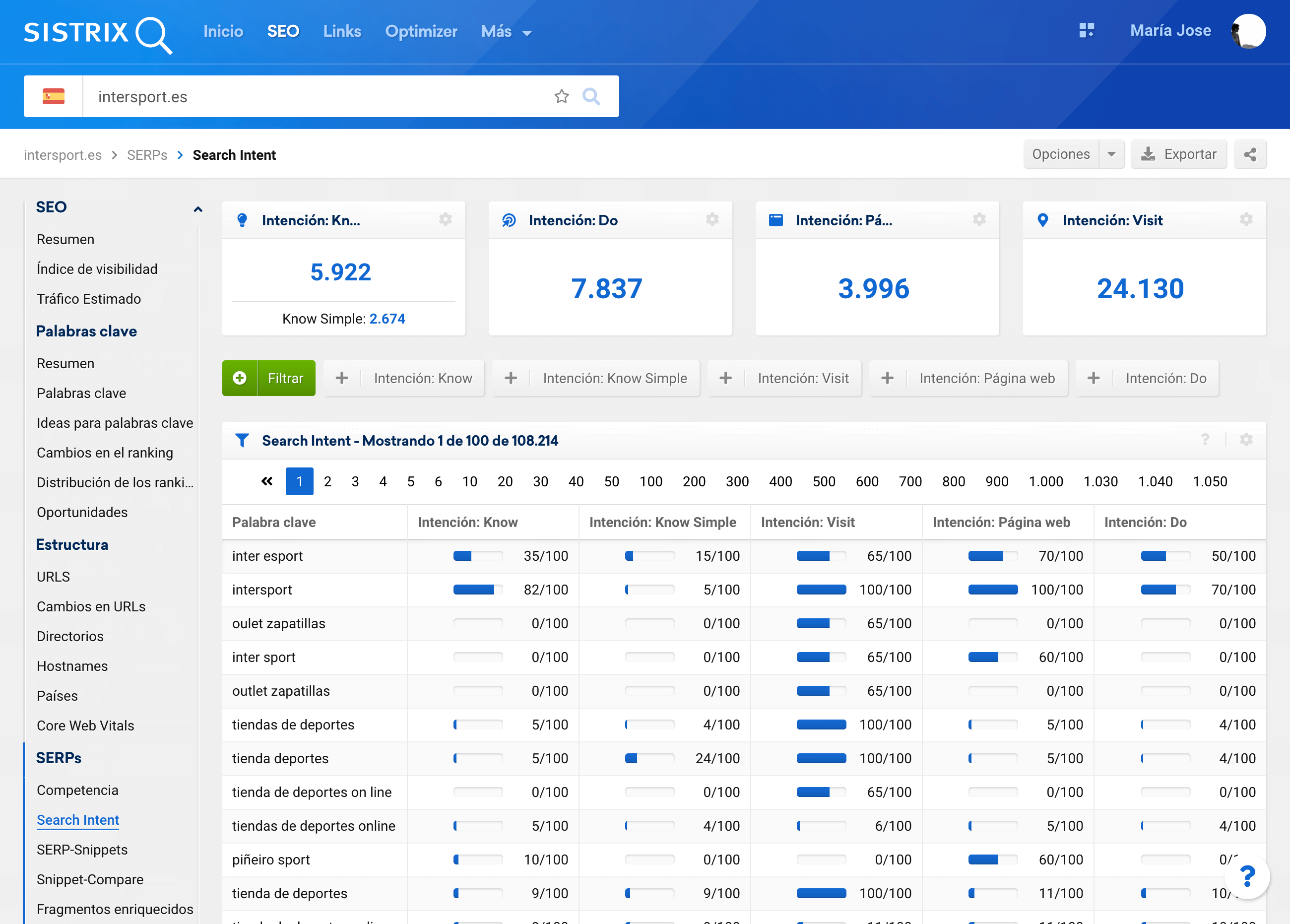
Bien, podemos extraer esta información y jugar con los datos para poder tener una idea más clara de cómo es la distribución de rankings basado en este criterio, principalmente, en la intención de búsqueda predominante de cada palabra.
¿Cómo agilizarlo en Excel o Google Sheets?
=SI.CONJUNTO(MAX(V2:Z2) = V2; $V$1;MAX(V2:Z2) = W2;$W$1;MAX(V2:Z2) = X2;$X$1;MAX(V2:Z2) = Y2; $Y$1; MAX(V2:Z2) = Z2;$Z$1)Trabajando y visualizando los datos: tablas dinámicas
Ahora ya tenemos todos los datos limpios, preparados y listos para poder analizarlos y sacar información que nos ayude a entender cuál es la visibilidad en base a rankings del proyecto o del competidor.
Mediante tablas dinámicas podemos agrupar los datos en base a distintas preguntas que nos podemos hacer para agilizar el análisis y entender dónde están las oportunidades.
Distribución de rankings: por tipo de palabra
Una vez tenemos todos los datos, podemos visualizar y contextualizar los datos, profundizando de lo más general a lo más específico.
Una primera idea es trazar la distribución de rankings global, lo cual nos dice que tenemos un 26% en el top 10.
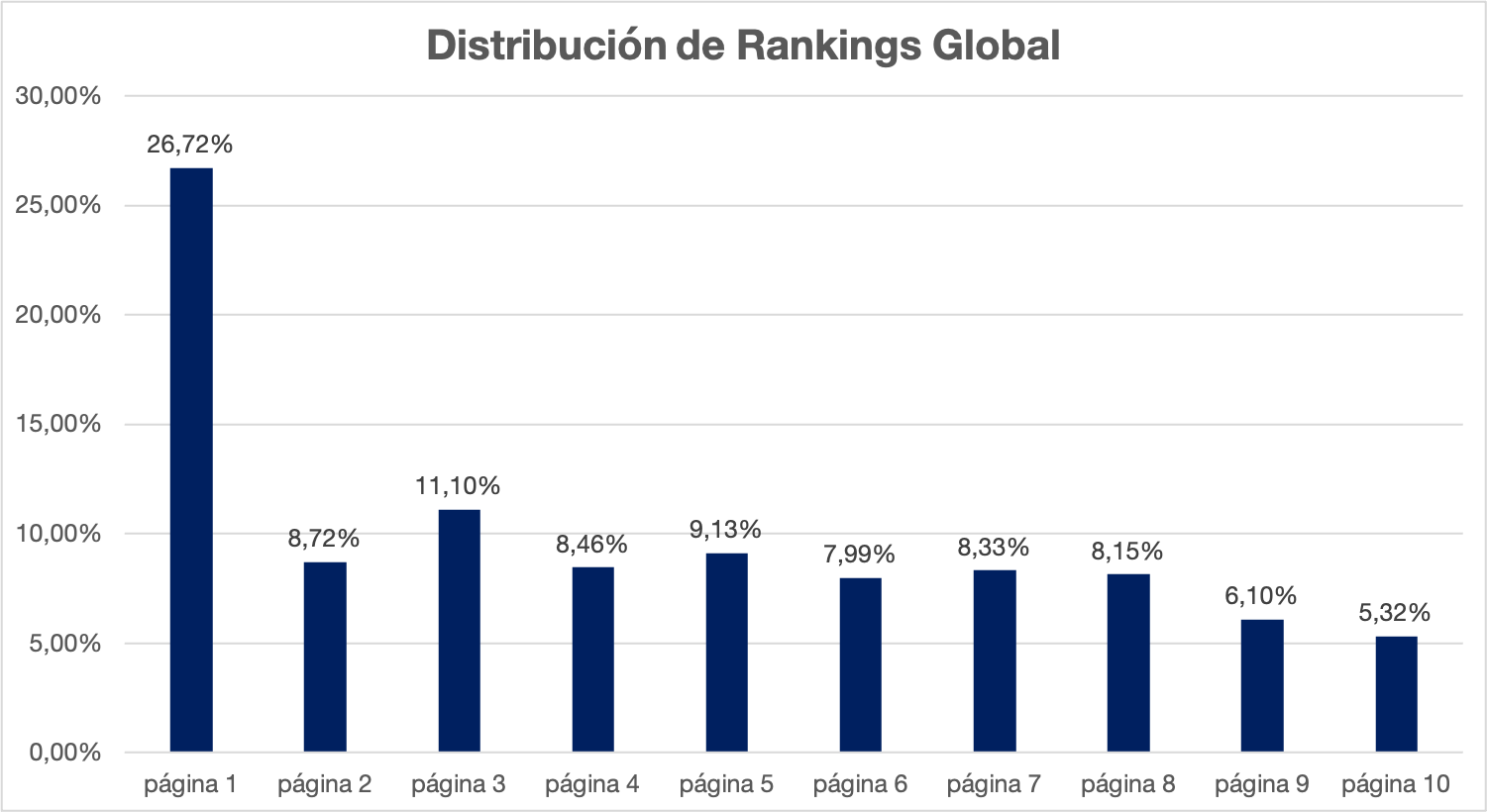
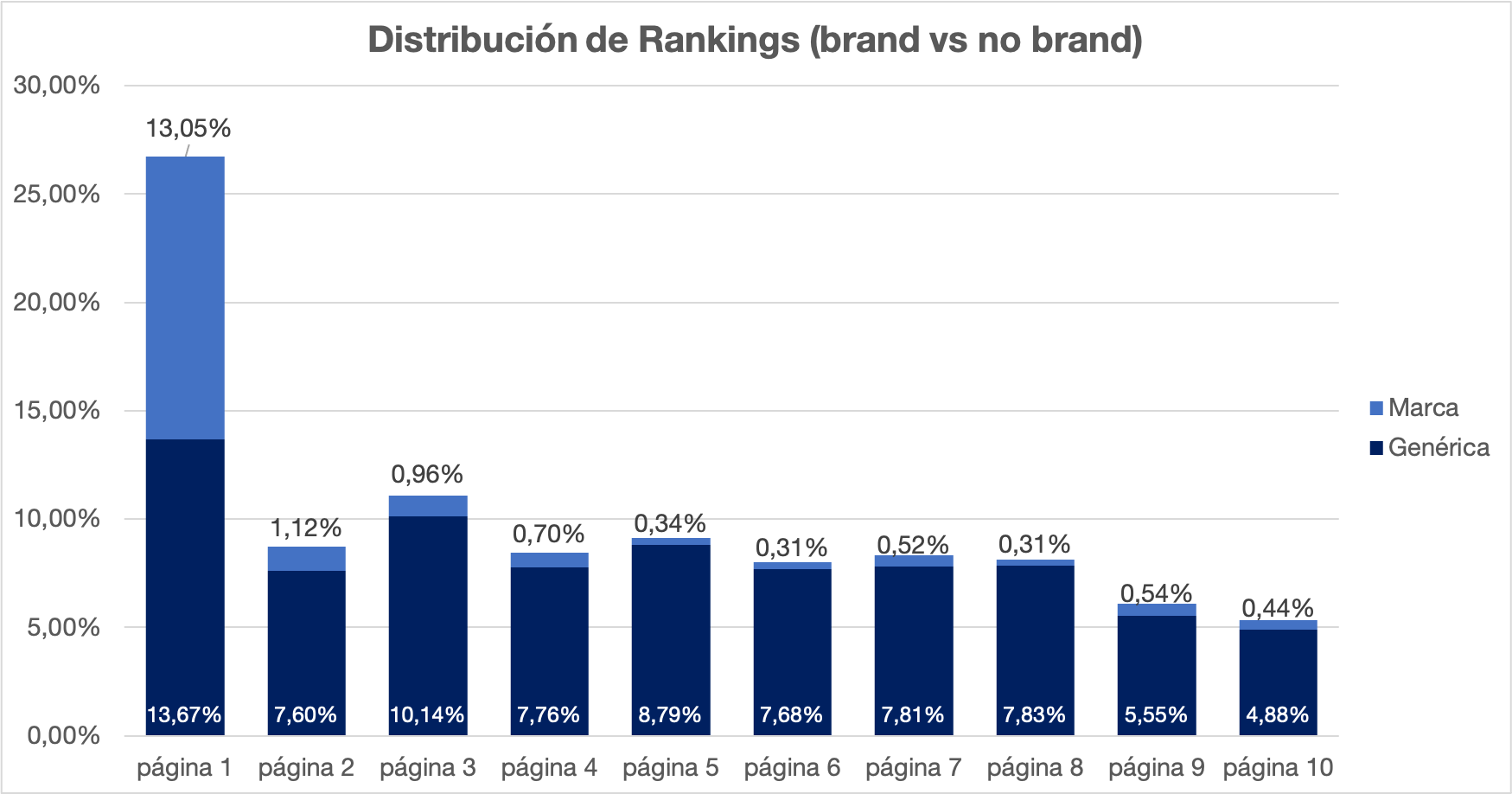
Ahora vemos la de marca vs no marca, ya observamos que solo un 13% son palabras clave relativas a usuarios que no nos conocen
Y también podemos verlo desde la perspectiva de palabras clave short tail vs long tail
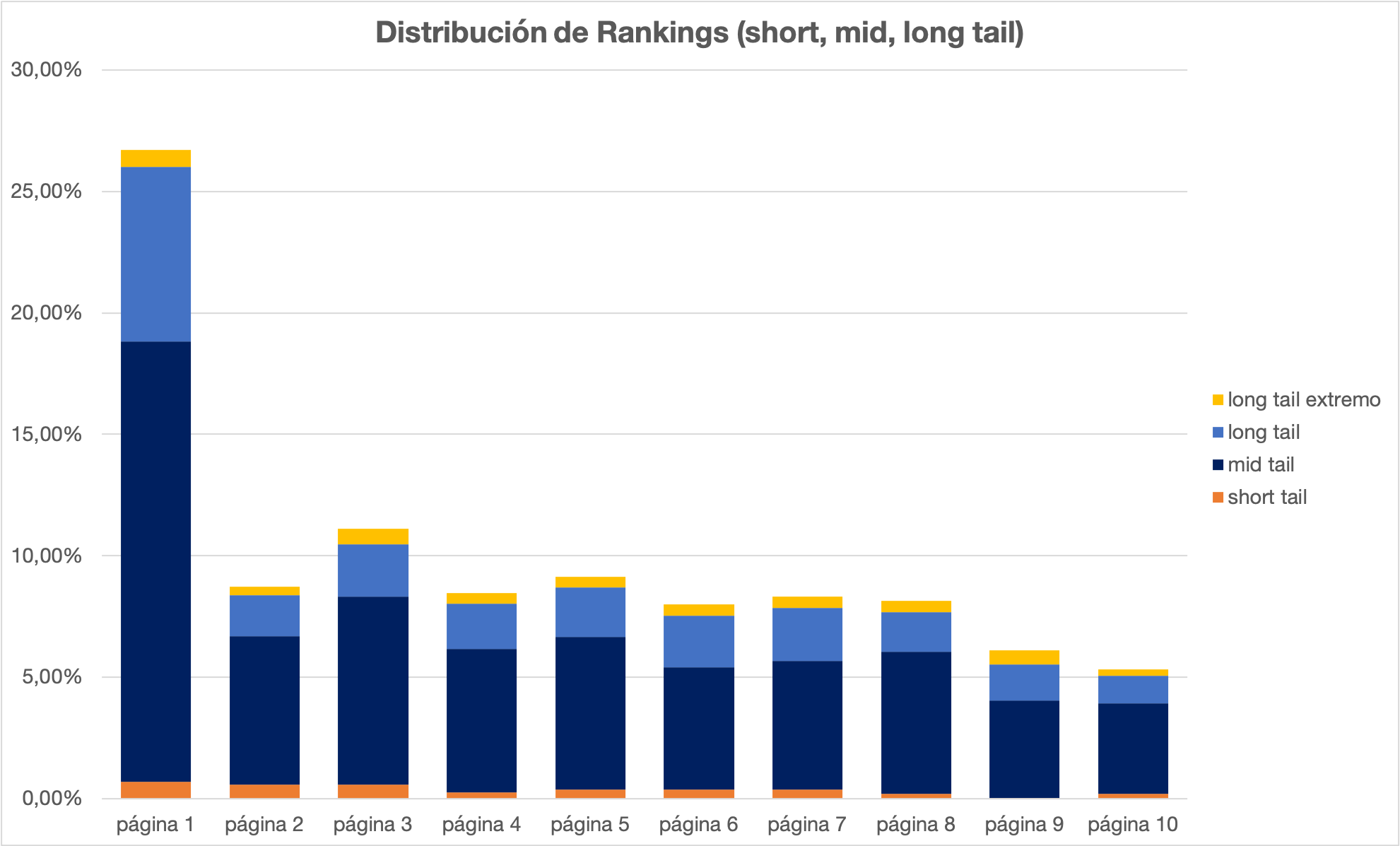
Con esta visualización ya podemos identificar dónde podemos poner foco para mejorar:
- Aumentar el número de palabras clave genéricas en el top 10
- Atacar palabras clave por tipo: long tail que será menos competido y short tail que ofrecerá mayor exposición
Distribución de rankings: por nivel de visibilidad y por secciones
Si vamos a una métrica más simplificada, una escala de 4 estados que nos ayuda a entender dónde se ubican los rankings y que solo las presentes en las 2 primeras barras nos pueden generar tráfico
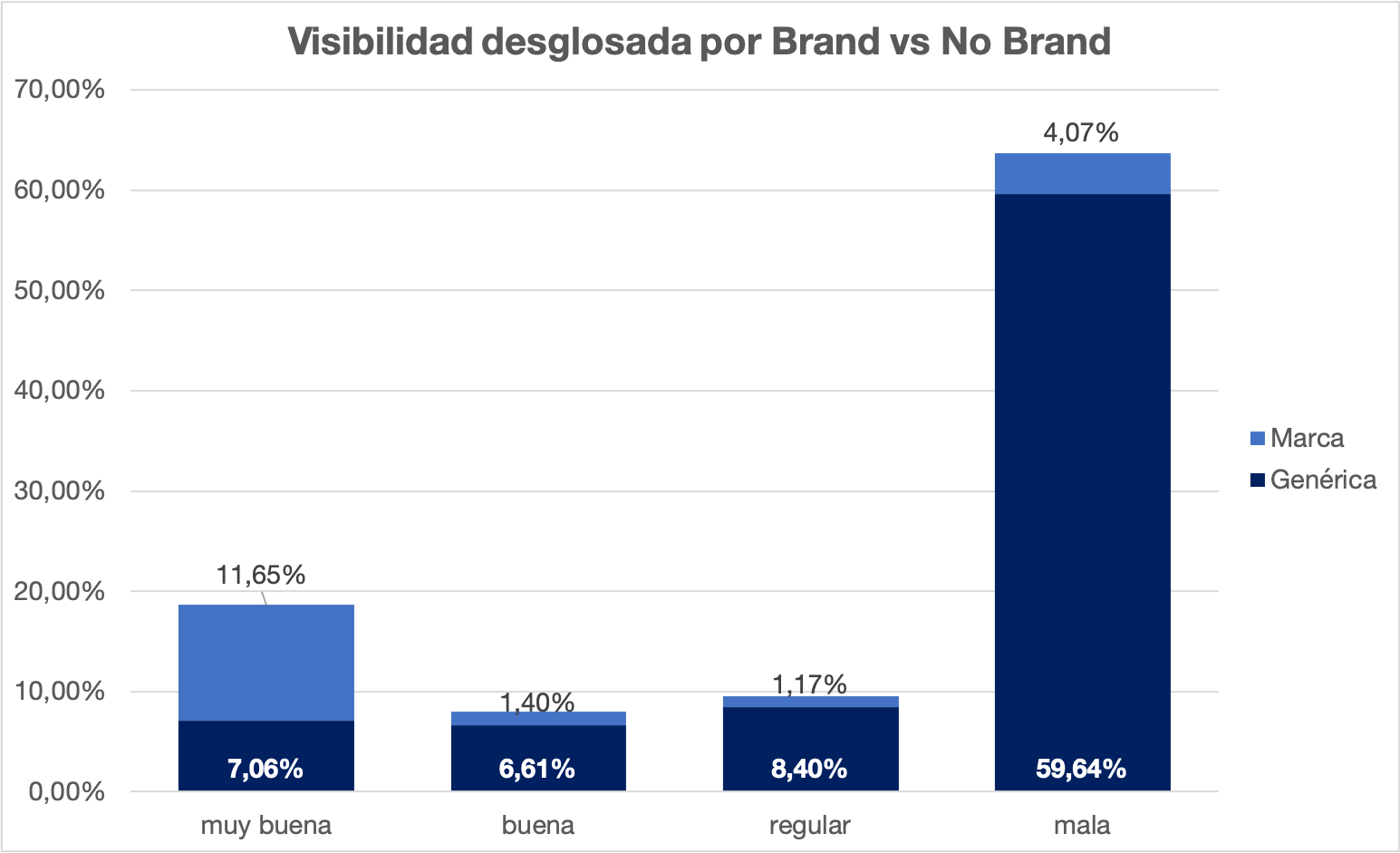
Si usamos el mismo enfoque pero añadimos el Path de las URLs, podemos identificar las secciones más fuertes a nivel de rankings totales y también el desglose de visibilidad, para ver esos grupos cómo se posicionan individualmente.
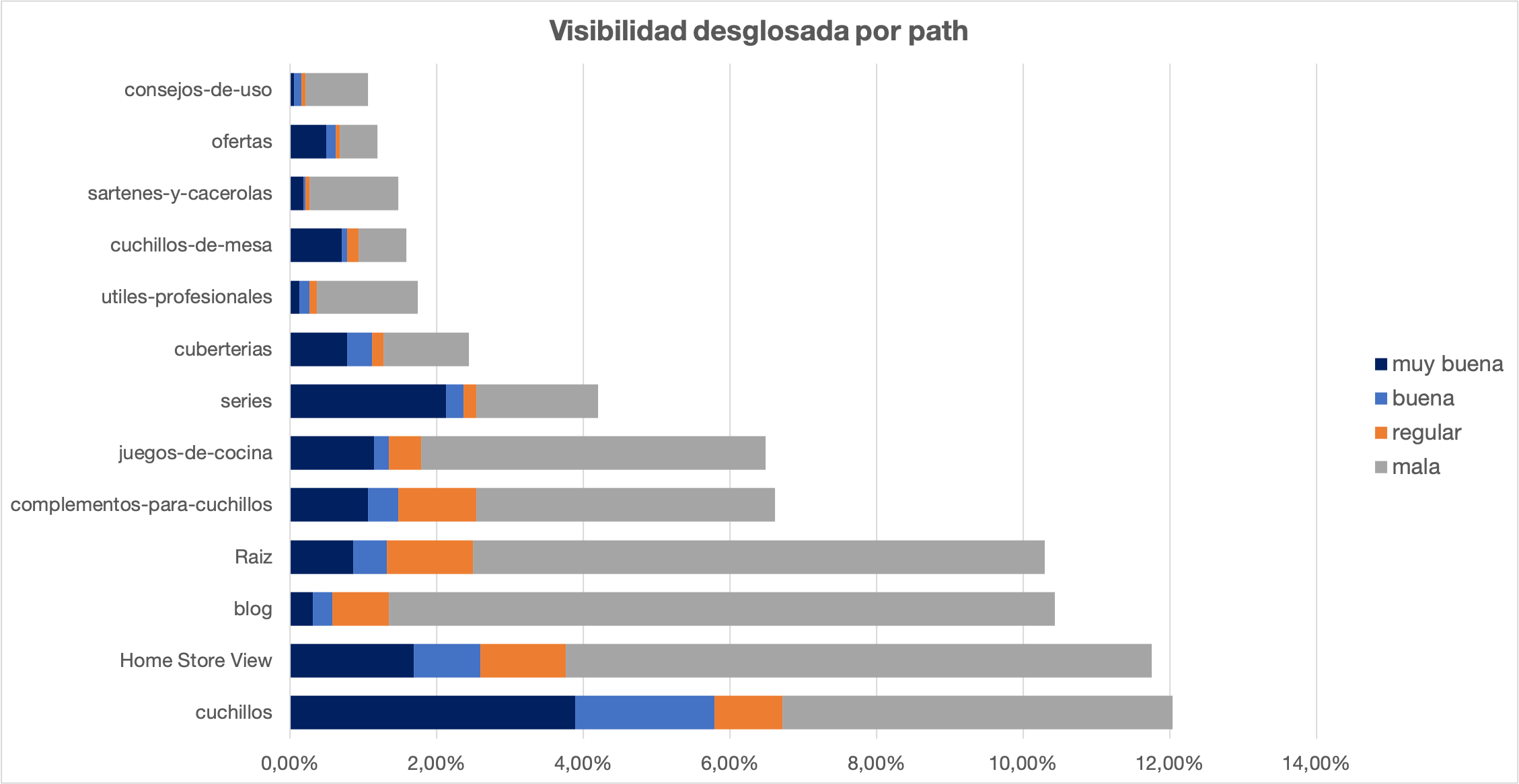
Con esta visualización ya podemos identificar dónde podemos poner el foco para mejorar:
- Qué secciones importantes no tienen una visibilidad «muy buena», por ejemplo Cuchillos, el 50% de palabras clave tienen visibilidad regular o mala.
- Qué secciones tienen mucha visibilidad global pero muy poca «muy buena» o «buena», por ejemplo, el Blog.
- Si cruzamos esta información con datos de volumen y competencia, podemos crear una matriz con las oportunidades por sección respecto a facilidad de posicionar, por ejemplo.
Distribución de rankings: por volumen/ competencia
Si usamos la misma métrica para ahondar en cómo de competidas son las palabras clave que posicionamos o las que no, nos puede abrir un poco más los ojos respecto a cómo estamos y cómo deberíamos estar.
| Visibilidad | Competencia Alta | Competencia Media | Competencia Baja |
|---|---|---|---|
| Muy buena | 0,42% | 0,08% | 18,21% |
| Buena | 0,62% | 0,05% | 7,34% |
| Regular | 0,47% | 0,23% | 8,87% |
| Mala | 3,01% | 1,82% | 58,88% |
En esta tabla nos podemos centrar en aquellas palabras clave que tienen visibilidad regular o mala y que además, tienen competencia media o baja
| Visibilidad | Volumen Muy Alto | Volumen Alto | Volumen Medio | Volumen Bajo | Volumen Muy Bajo |
|---|---|---|---|---|---|
| Muy buena | 0,23% | 0,16% | 0,62% | 0,29% | 17,41% |
| Buena | 0,03% | 0,10% | 0,67% | 0,13% | 8,02% |
| Regular | 0,10% | 0,23% | 0,88% | 0,23% | 9,57% |
| Mala | 0,67% | 1,19% | 4,41% | 2,65% | 54,79% |
Sin embargo en esta otra tabla nos podemos centrar en aquellas palabras clave que tienen visibilidad regular o mala y que además, tienen volumen medio o alto. Si somos una web un poco más modesta, pues la estrategia puede ser diferente.
Distribución de rankings: por intención de búsqueda
Por último, también podemos usar la información de intención de búsqueda para extraer varias lecturas más específicas sobre la visibilidad y la distribución de los rankings.
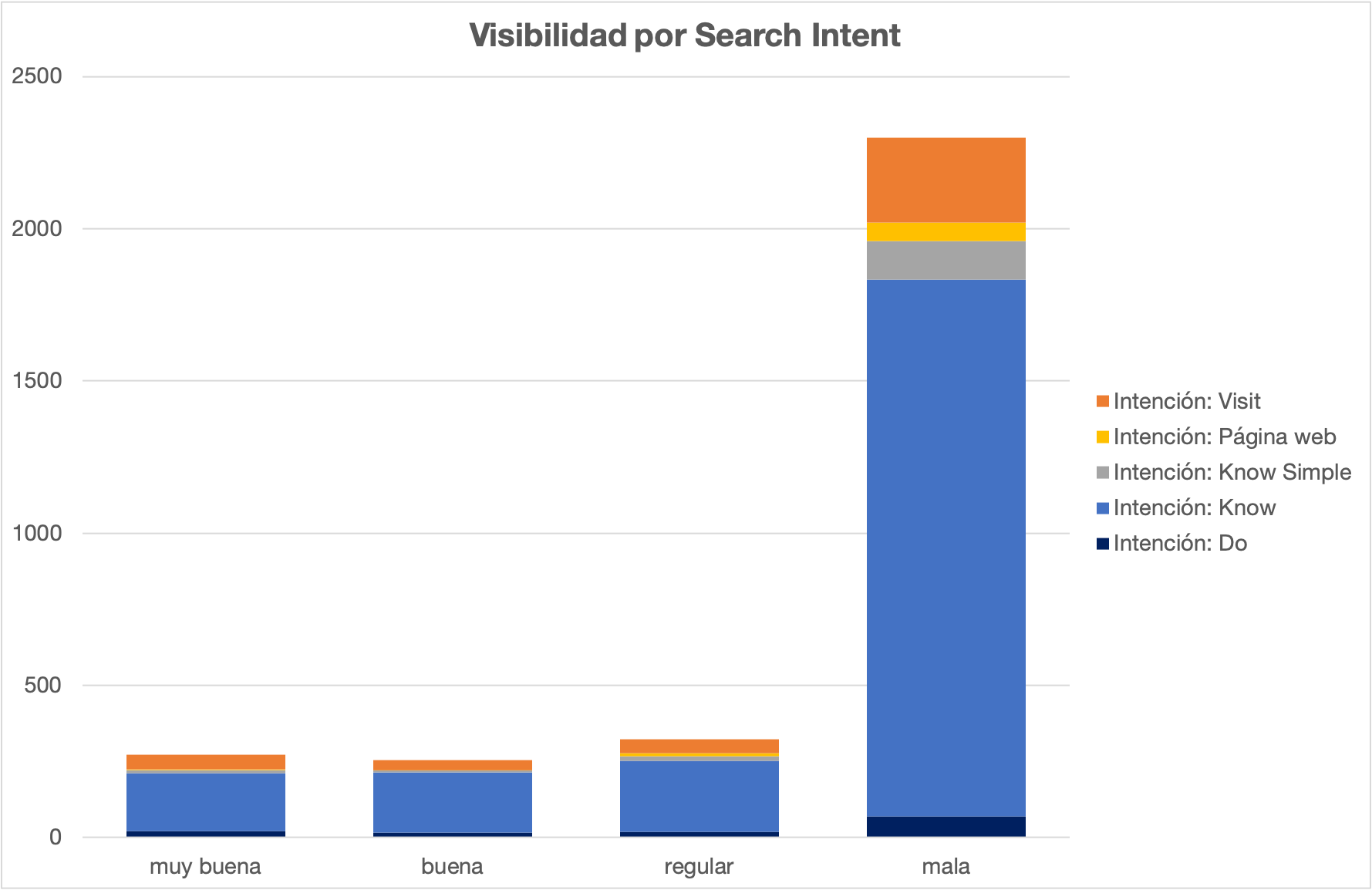
En este sentido, ya podemos hacernos una idea de qué tipo de palabras se posicionan mejor o peor respecto a lo que espera encontrar el usuario al hacer la búsqueda:
- Encontrar información concreta o general (Know o Know simple)
- Ir a un sitio físico (Visit)
- Navegar por la web de una marca (Web)
- Realizar una transacción (Do)
Por último, si cruzamos esta información como en las tablas anteriores para construir una matriz de oportunidades por competencia baja o tráfico alto, e incluso por secciones de la web, nos resultará una matriz accionable de mucho valor.
Conclusiones y aprendizajes
La explotación, análisis y visualización de datos puede comenzar con un simple Excel o hoja de cálculo de Google Sheets, tan solo hay que tener claras unas premisas antes de empezar a tocar datos.
Como es obvio, Excel es una herramienta que puede servir a un porcentaje muy alto de proyectos, pero no debemos dejar de lado opciones que permitan escalar nuestras metodologías de análisis.
Los proyectos de mayor envergadura necesitarán manejar tecnologías de bases de datos que permitan una mayor flexibilidad para el manejo de datos más exigente que con proyectos pequeños.
Sea como fuera, este post tan solo trata de mostrar que el análisis de datos no tiene por qué ser algo difícil, sofisticado ni que requiera expresamente el conocimiento técnico de ciertas soluciones (Python, R, SQL, etc.), pero si es recomendable adquirir conocimientos de ese tipo para llevar las metodologías más básicas que hoy hacemos en Excel o Sheets a sistemas de bases de datos.
En lo que a SEO se refiere, los análisis de datos son una habilidad presente y futura que nos seguirá definiendo como expertos y que, sin duda, cuanto más trabajemos y pulamos, más nos ayudará a realizar diagnósticos de distintas situaciones en nuestros proyectos, así como a identificar oportunidades de mejora desde lo más general a lo más particular.
Para finalizar, espero que os pueda ser útil y por si os puede ayudar más, os adjunto una hoja de Sheets con los campos calculados y sus fórmulas: https://docs.google.com/spreadsheets/d/1532arxMJEv8UhDf7tB7iBT8npZJYnquo4qbdtQevnJo/edit?usp=sharing