

La forma en la se desarrolla y diseña una web para presentar el contenido puede ser un punto clave para garantizar la accesibilidad de los motores de búsqueda y, no incurrir en ineficiencias respecto a rastreo. Algunos proyectos pueden sufrir problemas de implementación al trabajar con contenidos que están bajo un «muro», ¿quieres saber los impactos que puede tener en SEO y qué proyectos pueden verse afectados?
Muros de registro
Los muros de registro son proyectos cuyo contenido solo estará disponible o se podrá consumir una vez nos hemos registrado. Un ejemplo muy habitual son suscripciones como Spotify, que proveen el contenido cuando accedemos desde nuestro login para consumir el contenido (en este caso, escuchar música).
La mayor desventaja a la que se enfrentan es satisfacer búsquedas de usuarios y ser capaces de mostrar un contenido afín, sin incurrir en prácticas prohibidas por Google como puede ser el cloaking (mostrar un contenido diferente al usuario y a Google).
Implicaciones SEO
En el pasado ya hablamos de Spotify y de lo que ocurrió con su visibilidad por mostrar un contenido a Google y otro muy diferente al usuario, un caso claro de cloaking claro. Pero lo cierto es que, con el paso del tiempo, han ido creciendo en visibilidad una vez que en 2018 se empezaron a incrementar los despliegues de actualizaciones Core tan intensivas que todos vivimos desde entonces.
El cloaking es un riesgo alto pero en la actualidad contamos con una matización por parte de Google que podemos resumir en los siguientes puntos clave:
- El cloaking busca engañar al usuario. Por lo que si se muestra un contenido para Google y otro totalmente diferente para el usuario: es cloaking.
- Si tenemos una web responsive puede que en la versión para dispositivo móvil no esté el contenido completo de la versión para dispositivo de escritorio: no es cloaking.
- Otros tipos pueden ser mostrar una notificación o una ventana emergente al usuario y que no se muestra para el Googlebot: la mayoría de las veces no se consideraría cloaking.
- Mientras no se engañe al usuario, tener un contenido que es un poco diferente está bien. Lo que nos deja en el lado seguro
Spotify en su momento mostraba contenidos algo diferentes para Google y para el usuario. Siguiendo el ejemplo que tomamos en 2016, «national philarmonic orchestra» en Google.co.uk, los contenidos que mostraba Spotify para el usuario por aquel entonces (2016):

Los contenidos que muestra Spotify para el usuario en la actualidad, con una advertencia indicando que son una muestra y que puedes acceder al contenido completo tras registrarte (muestran un listado de canciones):
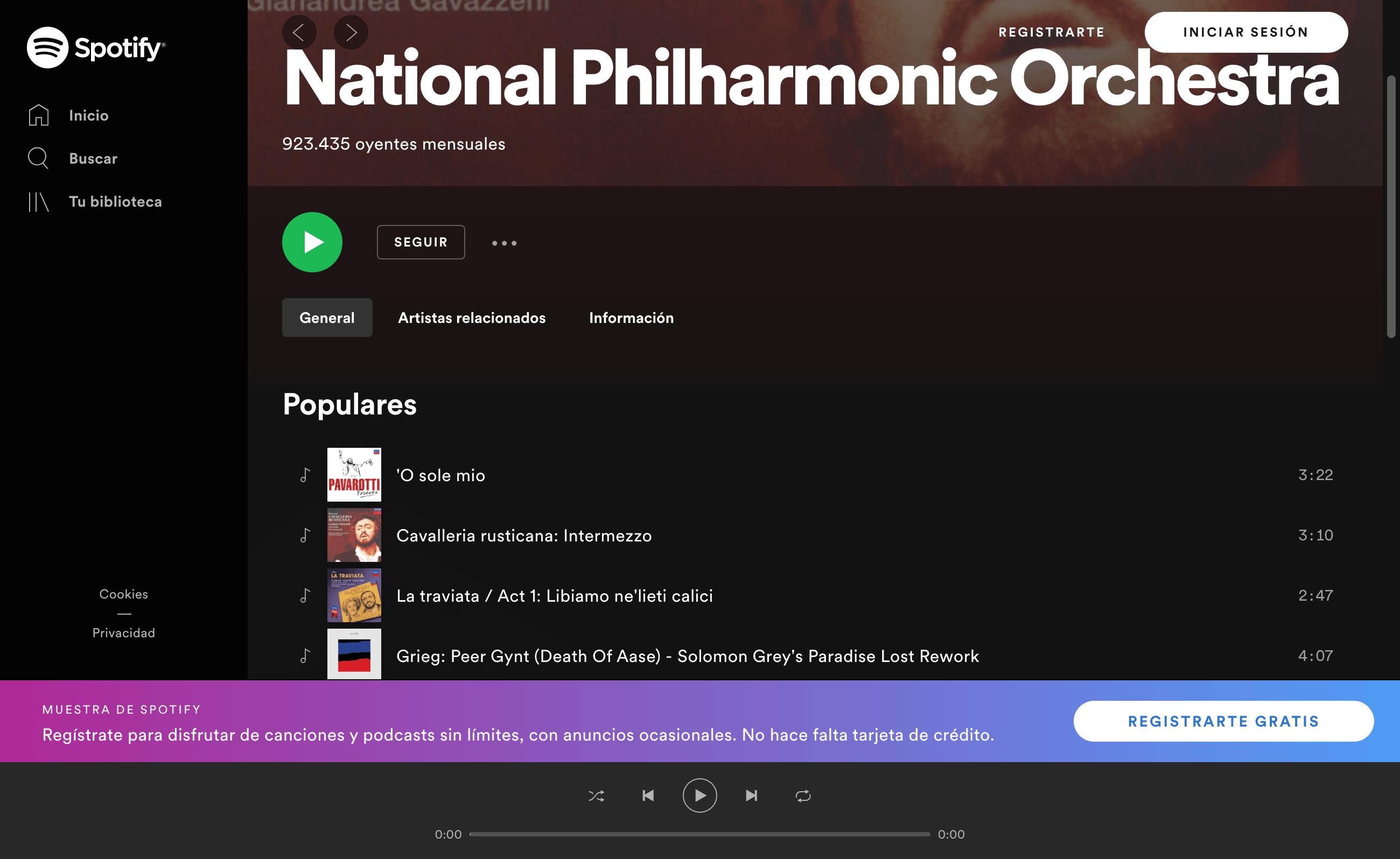
Los contenidos que muestra Spotify para Google en la actualidad corresponden con la misma lista de canciones que ve el usuario, obviando los enlaces de «Regístrate»:

Como se puede apreciar son contenidos muy similares, con algunos matices:
- Si el usuario que navega tiene ya una cuenta de Spotify se le abrirá el reproductor.
- Si no, se le mostrará el reproductor pero no podrá reproducirlo hasta que no cree o acceda a una cuenta.
- Desde la caché de Google, sin embargo, si se podrá reproducir parcialmente la música.
En ambos casos, se nota una mejora considerable a nivel de contenido y maquetación. Por lo que se percibe un esfuerzo por ser relevante y ofrecer a los usuarios un contenido que encaje en búsquedas de nombres de los discos, las bandas y las canciones (como mínimo).
Por tanto, para ambos ocurre que Spotify está intentando adaptar el contenido para satisfacer la intención de búsqueda, con algo más difícil de controlar como pueden ser aquellos casos en los que la intención sea ambigua o mixta: con intenciones Know (leer contenido o información) o Do (hacer algo, en este caso, reproducir música).
El punto clave de este tipo de situaciones es elegir el método y no ofrecer un contenido radicalmente diferente:
- Hacer una correcta detección del User Agent y hacerlo coincidir con lo que se debe mostrar en cada caso.
- Identificar la IP de Googlebot para mostrarle la versión sin login/regístrate.
- Tratar de identificar si el visitante ya tiene cuenta para trazar correctamente el recorrido y abrir el reproductor web o la app, según corresponda.
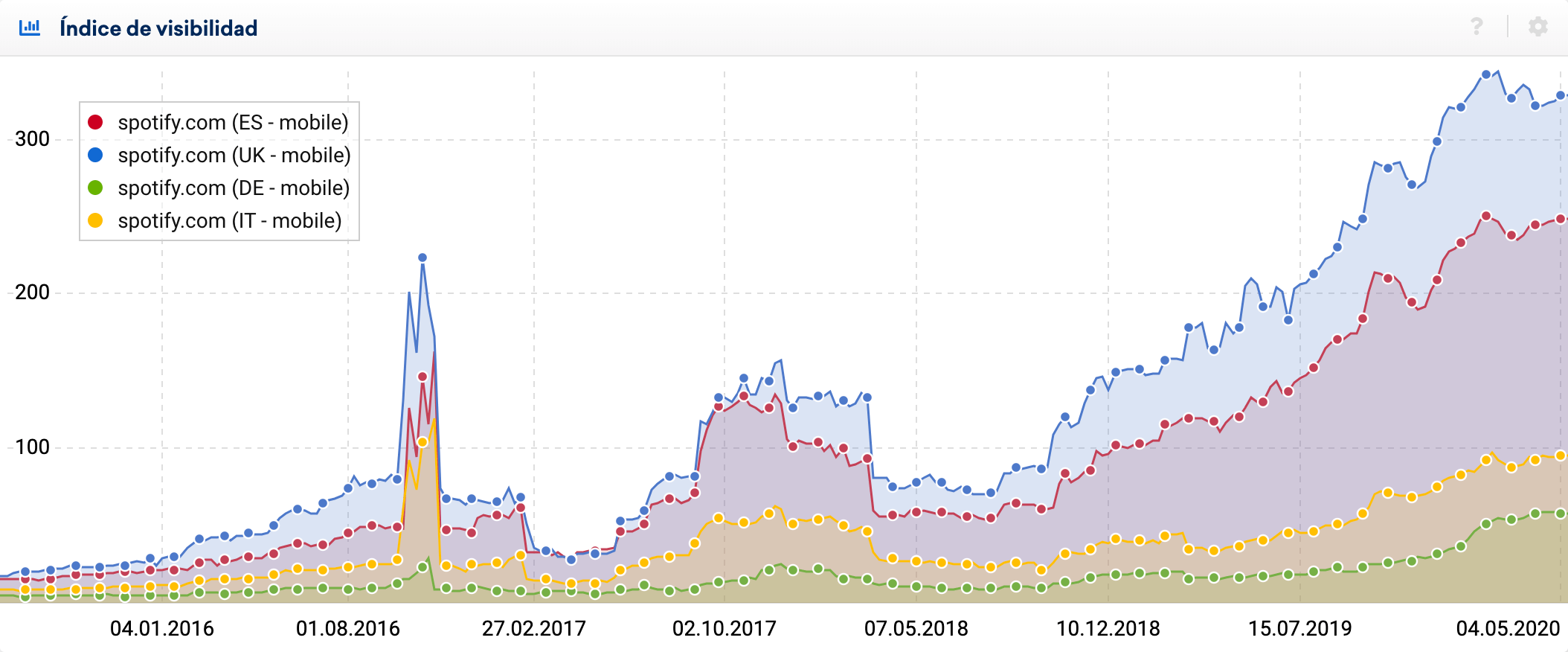
Sin entrar en mucho más detalle, el rendimiento en términos de visibilidad desde noviembre de 2016, es evidente:
Muros de pago
Los muros de pago han cogido mucha fuerza y se han extendido en proyectos de noticias como son los medios de comunicación. Los sitios de noticias han habilitado contenidos de pago para ampliar su modelo de negocio y no basarse únicamente en la publicidad tradicional basada en impresiones por páginas vistas donde los anunciantes podían aparecer.
El concepto «muro de pago» hace referencia a las barreras que existen para acceder al contenido, que en este ejemplo sería la suscripción o el registro.
Siguiendo esta definición, podría entrar perfectamente el caso de Spotify visto en el primer punto, pero hemos querido diferenciarlos por la entidad propia que han adquirido los medios con esta nueva forma de servir las noticia. También después de ver pasar a la historia el modelo First Click Free.
Los muros pueden ser totalmente de pago, pueden ser mixtos (algunos abiertos y otros de pago), pueden permitir muestras gratuitas (limitadas para consumir y evaluar si te quieres suscribir), etc.
Un ejemplo de muro de pago sería este:

No obstante, Google identifica en sus guías dos conceptos o tipos de muros de pago que se pueden combinar entre sí:
- El cupo por usuario, que consiste en permitir que los usuarios accedan a determinada cantidad de artículos gratuitos y, una vez alcanzada esa cantidad, empezar a mostrar el muro de pago.
La existencia del muro de pago afecta a la experiencia de usuario en función de los contenidos a los que el usuario tenga acceso cada periodo de tiempo.
No hay un mínimo ni un máximo, pero según Google,
«Los editores de noticias diarias les convendría permitir de 6 a 10 artículos gratuitos por usuario al mes».
Google sobre cuánto contenido gratuito se debe ofrecer
https://support.google.com/webmasters/answer/7532484?hl=es
Esto se recomienda de cara a ofrecer una buena experiencia a nuevos suscriptores y llamar la atención de nuevos usuarios que se conviertan en suscriptores. Analizar el porcentaje de usuarios que vienen del buscador y que pasan por el muro de pago, puede ser el punto de partida para ir ajustando la cantidad de artículos gratuitos a ofrecer.
- La introducción, que consiste en mostrar solo una parte del contenido de los artículos y, para leer el resto se requiere ya de suscripción o registro.
Esta introducción del artículo ofrece a los usuarios un «spoiler» de lo que encontrarán en el artículo y actúa de anzuelo para captar su atención y generarles una expectativa del valor del contenido que le haga tener ganas de saciar su curiosidad.
Según los análisis de Google:
«La satisfacción general de los usuarios empieza a disminuir significativamente cuando aparecen muros de pago en más del 10 % de las ocasiones, lo que suele indicar que aproximadamente un 3 % de la audiencia ha visto el muro de pago»
Google sobre dar acceso gratuito limitado a un sitio web
https://support.google.com/webmasters/answer/7532484?hl=es
Implicaciones SEO
El inconveniente es igual que el que tenían servicios como Spotify y se llama cloaking o encubrimiento. Dicho de otro modo, esa práctica perseguida por Google y que consiste en mostrar contenidos distintos a usuarios y a Google.
Esto es un caso especial y no es cloaking estricto, ya que no existe ninguna malicia ni mala fe para engañar a Google y al usuario con distintos contenidos, sino que por una cuestión de negocio se muestran contenidos parciales o totales cuando corresponde.
¿En qué nos deberíamos fijar en esos casos?
- Añadir una clase CSS a la sección de pago:
<body> <div class="non-paywall"> Contenido abierto </div> <div class="paywall"> Contenido de pago </div> </body> </html>
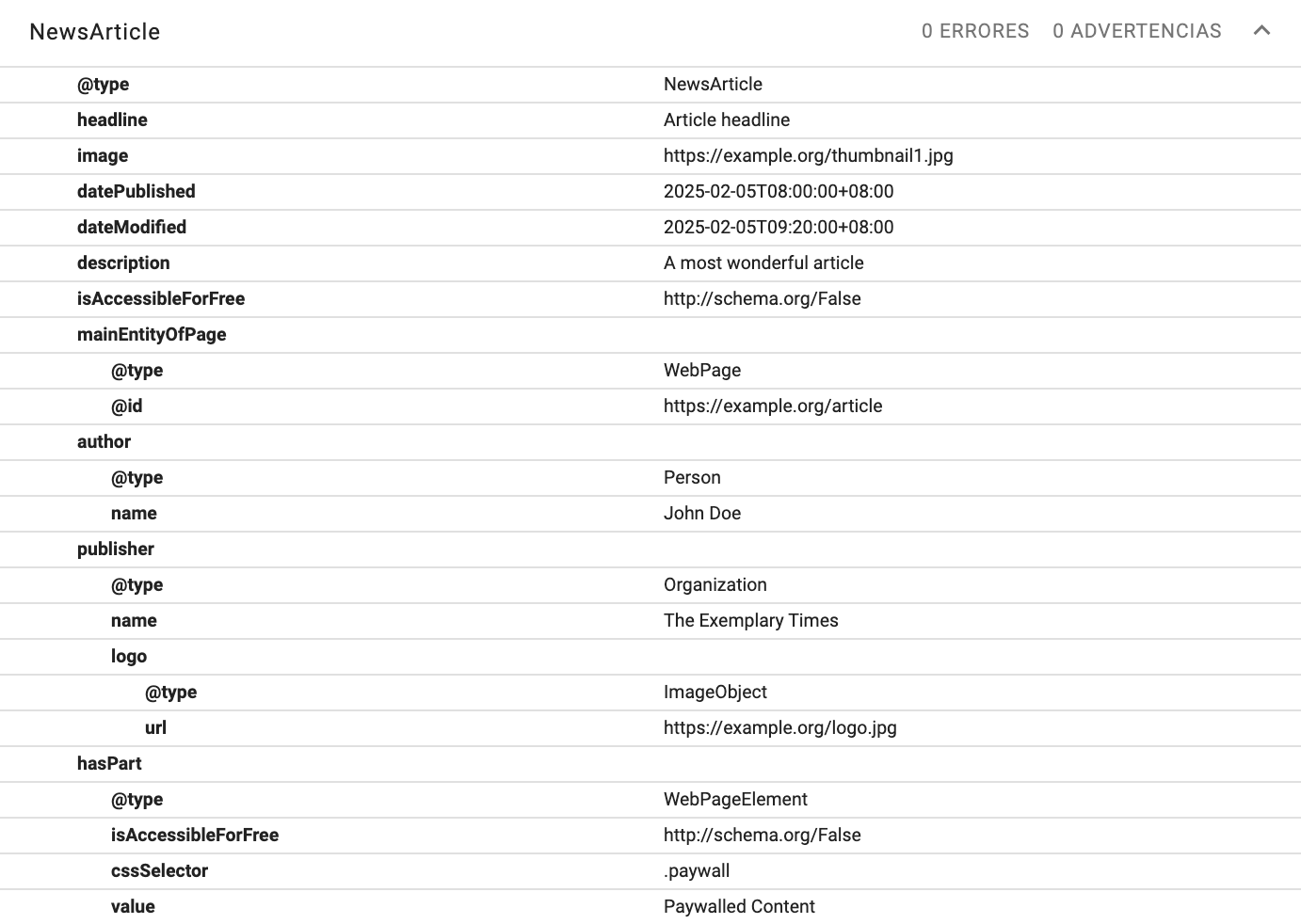
- Añadir datos estructurados vía JSON-LD de NewsArticle para marcar si el contenido es accesible o no, con la propiedad isAccessibleForFree:
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "NewsArticle",
"mainEntityOfPage": {
"@type": "WebPage",
"@id": "https://example.org/article"
},
"headline": "Article headline",
"image": "https://example.org/thumbnail1.jpg",
"datePublished": "2025-02-05T08:00:00+08:00",
"dateModified": "2025-02-05T09:20:00+08:00",
"author": {
"@type": "Person",
"name": "John Doe"
},
"publisher": {
"name": "The Exemplary Times",
"@type": "Organization",
"logo": {
"@type": "ImageObject",
"url": "https://example.org/logo.jpg"
}
},
"description": "A most wonderful article",
"isAccessibleForFree": "False",
"hasPart":
{
"@type": "WebPageElement",
"isAccessibleForFree": "False",
"cssSelector" : ".paywall"
}
}
</script>
</head>- Validar la implementación para chequear si hay errores de marcado:
- Confirmar que Google puede rastrear el contenido. Principalmente permitiendo a los User-Agent de Googlebot y Google News rastrear ambos tipos de contenido (el abierto y el de pago), así como los recursos que sean precisos para que el contenido sea consumido (CSS, JS, imágenes, etc.).
Conjuntamente con esto, algunos medios están usando la meta etiqueta «noarchive» para decirle a Google «no quiero que cachees esto» pero manteniendo las instrucciones de rastreo e indexación intactas. La etiqueta se puede crear de forma general para todos los robots o de forma específica para robots concretos, tal y como se indica a continuación:
<meta name="robots" content="noarchive"> <meta name="Googlebot" content="noarchive"> <meta name="Googlebot-News" content="noarchive">
¿Vamos a poder ver cómo lo están haciendo los medios para lograr aprendizajes?
Es algo que por el momento es difícil de ver. Sobre todo cuando nos referimos a implementaciones correctas. Ya que si utilizan detección de IP para identificar a Google no vamos a saber qué contenido están mostrando a Google realmente, a no ser que no estén utilizando la etiqueta «noarchive» y podamos ver la caché.
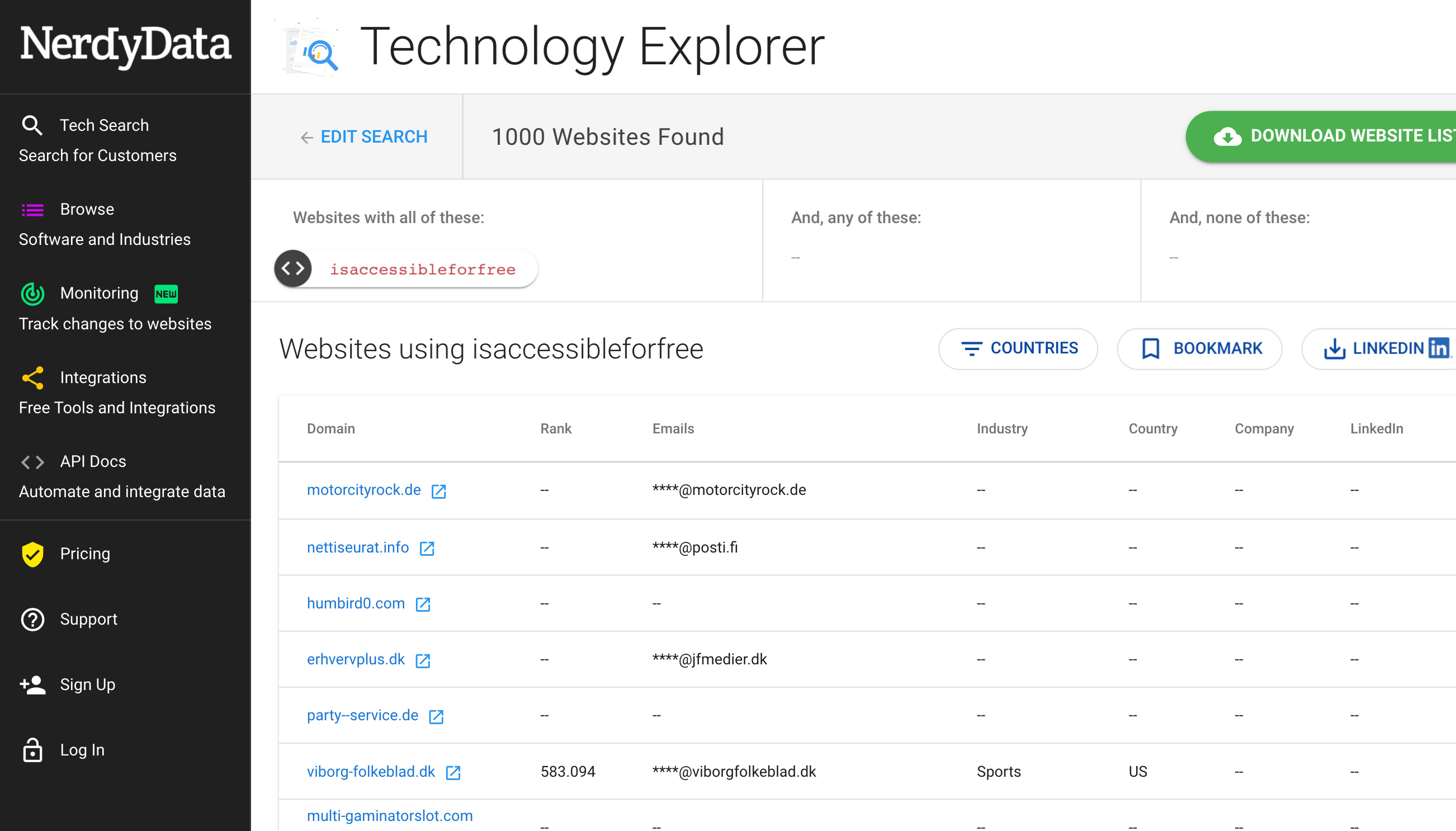
No obstante, se puede observar cuánta gente hace uso de la propiedad isAccessibleForFree tanto en las páginas indexadas por Google como en buscadores de código como Nerdy Data:
Muros de edad
Otra variante de muro de contenido la encontramos en aquellas webs que tiene una restricción para permitir o denegar el acceso a usuarios que no sean mayores de edad. En este sentido, los casos más usuales son sitios web para adultos como pueden ser las bebidas alcohólicas que por ley deben utilizar una solución para validar que el visitante es mayor de edad, antes de mostrar ningún contenido.
Implicaciones SEO
En este punto la gravedad radica en dos aspectos y va a estar sujeta a la forma de implementar esta primera interacción con el usuario (y con Google):
- Accesibilidad básica: si se implementa como un Pop Up o modal que se ubica delante del contenido principal (.html) o si se usa Javascript u otros métodos para mostrar un selector que deniega ningún otro enlace o acceso para que Google siga rastreando.
- Interstitials o Pop Ups molestos: con las actualizaciones de Google, con este aspecto hay que ser cautos con el uso de elementos que puedan usurpar el contenido principal y empeorar la experiencia de usuario.
Como recordatorio de cómo tratar los Pop Up o intersticials adjunto una imagen descriptiva de usos incorrectos:

Y de usos permitidos:

No obstante, la posición de John Mueller está clara:
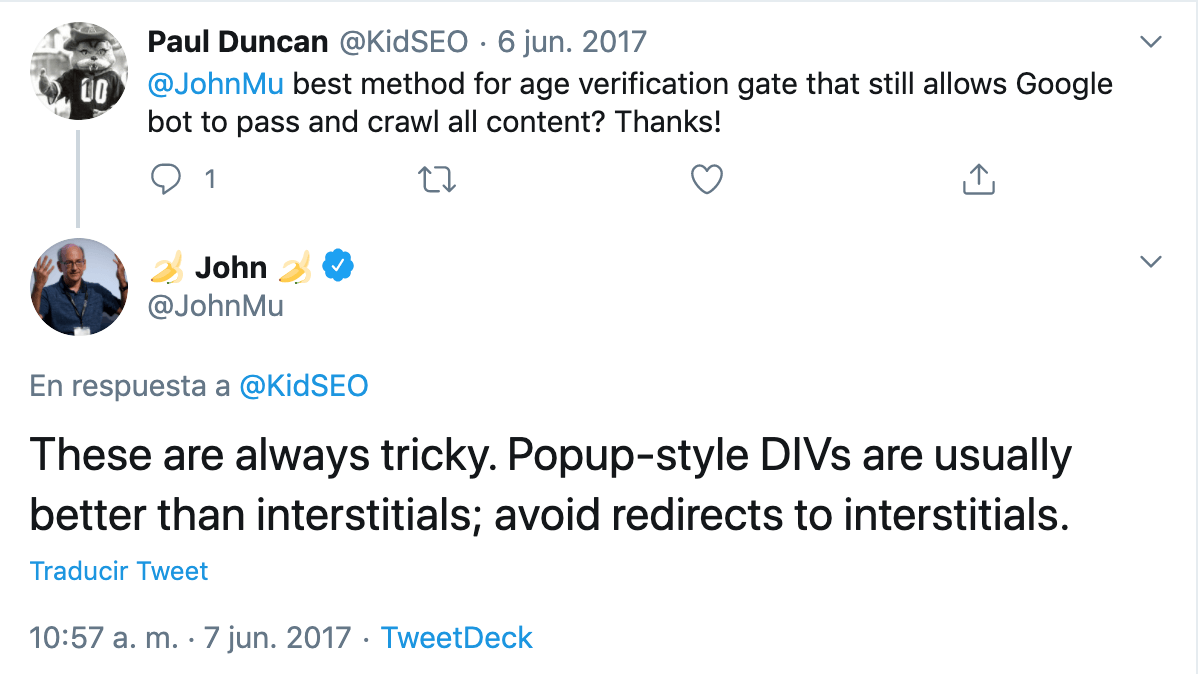
Por tanto, habría que plantearse, según estos criterios, que el selector de edad de un proyecto de estas características se haga de alguna de estas maneras:
- Detección del User-Agent, que podría utilizarse para detectar si el visitante es una persona real o un robot de búsqueda y enviar al usuario real a la página de verificación de edad y al robot al contenido. Sigue siendo cloaking y habría que considerar los puntos que Google tiene en cuenta en sus guías de buen uso.
- Redirección 302 hacia la URL para verificar la edad. Sería otra opción aparentemente sensata por la que los usuarios son redirigidos temporalmente a una página separada de verificación de edad y luego, enviados al contenido. Esto tiene sentido para los usuarios pero tiene efectos no tan óptimos para el Googlebot.
- Usar Javascript/CSS, o sea, un cuadro emergente superpuesto al contenido. De este modo en lugar de enviar a los usuarios a una página separada para introducir su fecha de nacimiento, aparecerá un cuadro emergente encima del Html. Por lo que el GoogleBot podrá rastrear el sitio web sin problemas.
Conclusiones y aprendizajes
En este artículo hemos hablado mayoritariamente sobre cloaking y muros de contenido, algunos de pago, otros de servicios y otros por requisitos especiales del contenido.
Es importante saber identificar este tipo de situaciones en un proyecto en el que colaboramos, aunque algunos son más obvios que otros.
Algunos de los principales aprendizajes que podemos extraer de las 3 casuísticas presentadas son:
- Pensamiento dual: Reflexionemos y proyectemos cómo sería la experiencia del usuario y cómo sería el rastreo que haría el Googlebot del contenido. La prioridad es el usuario, pero la captación orgánica suele ser una fuente de tráfico muy importante en muchos proyectos digitales.
- Evitar la complejidad y abrazar la simplicidad: El contexto de un proyecto puede complicarse mucho y debemos valorar cuál es la opción más sencilla para nuestro caso y también para tratar de hacerla escalable para un futuro, pensando en algo fácil de mantener y hacer crecer.
- Analizar y probar para ir ajustando la situación más ideal: No hay implementaciones estándar válidas para todos los casos que nos permita generalizar. Por lo tanto es necesario analizar y hacer seguimiento a las implementaciones de inicio e ir optimizándolas en base a los datos recogidos.
Esperamos que os haya podido aportar ideas y opciones para las casuísticas explicadas y esperamos vuestro feedback en los comentarios :)
Referencias
Cloaking (Directrices de Calidad, Google)
Muestras de contenido flexible (Google Guidelines)
Cómo usar schema.org JSON-LD para indicar contenidos con muro de pago (Google Developers)
How to diagnose Cloaking (Mike King, abril 2020)
Google: Different Content for Googlebot & Users Can Be OK (Roger Montti, abril 2020)
How To Serve Age Verification Pages to Google For Alcohol Sites (Barry Schwartz, octubre 2008)
Google SEO & Using Age Verification Gates (Jennifer Sleg, junio 2017)
When, Why & How to Use the Noarchive Tag (Brian Harnish, abril 2020)
Contenidos de pago en Google (Emilio Rodríguez, abril 2020)
Descripción general de los rastreadores -user agents- de Googleuser (Google Guidelines)
Google Won’t Hide News Behind Paywalls (Barry Schwartz, marzo 2020)
Google Shows Paywall Content in Featured Snippets (Roger Montti, octubre 2019)
Paywalls & SEO: A Winning Strategy (Chuck Price, junio 2019)
The Unusable and Superficial World of Beer and Alcohol Websites (Louis Lazaris, diciembre 2009)