
¿Cómo te ayudará esta guía?
Para hacer un buen uso de nuestro tiempo aprendiendo a manejar todas las funciones de la herramientas SISTRIX, necesitamos asegurarnos de que todos estamos preparados. Con la guía para principiantes de SISTRIX aprenderás todos los conceptos básicos importantes – un requisito importante para nuestro seminario.
Contenido
- ¿Cómo funciona Google?
- 6 buenas razones para hacer SEO
- SERPs de Google
- Dominio, subdominio, host y URL
- Factores de posicionamiento en Google
- Google como fuente de éxito SEO
- Glosario
- Fuentes relacionadas
¿Cómo funciona Google?
Google es el motor de búsqueda más utilizado en Europa – en Alemania la cuota de mercado es incluso superior al noventa por ciento. Por lo tanto podríamos decir que Google tiene control sobre el mercado de búsqueda y determina qué métodos de SEO están permitidos y cuáles no.
Cuando se realiza una búsqueda en Google, este muestra las listas de resultados casi en tiempo real. Pero, ¿cómo selecciona Google las páginas web que coinciden con la consulta de búsqueda?
El proceso simplificado:

Crawler
Googlebot rastrea (busca) miles de millones de páginas web al día en busca de contenido nuevo y actualizado y las añade a su índice.
Index
Para que un sitio web se encuentre mediante la búsqueda en Google debe estar incluido en el índice de Google. Allí es donde Google almacena información sobre las páginas encontradas.
Algoritmo de ranking
Cuando se inicia una búsqueda se busca una respuesta adecuada utilizando el algoritmo de posicionamiento.
SERPs
Google utiliza 200 señales para buscar en su índice el mejor resultado para la búsqueda realizada. Los resultados de búsqueda (SERPs) se reproducen como resultado.
Puedes encontrar más información sobre este tema en nuestro artículo de Pregúntale a SISTRIX «Rastrear e indexar sitios web extensos«.
6 buenas razones para hacer SEO
- SEO es gratis. En primer lugar, no hay costes (en comparación con Google Adwords) para ser mostrado en los resultados de búsqueda orgánica de Google.
- SEO trae tráfico relevante. Si interpretas correctamente las intenciones de búsqueda de tus usuarios y les proporcionas la respuesta apropiada (página), el SEO es una fuente de tráfico cualitativamente valiosa.
- SEO es más relevante que SEA. El 93,21% de los clics en los resultados de búsqueda de Google van a los resultados orgánicos.
- Reducir la competencia a través del SEO. Las posiciones de ranking en las SERPs son limitadas (normalmente 10 resultados/página). Con un buen SEO podrás desplazar a la competencia obteniendo rankings por palabras clave y generando una mayor presencia en las listas de resultados de Google.
- SEO fortalece la imagen. El conocimiento de la marca para los grupos objetivo puede mejorarse a través de una mayor visibilidad en los resultados de los motores de búsqueda.
- SEO es medible. El rendimiento SEO de un sitio web es, a través de la herramienta SISTRIX, medible y, lo que es más importante, comparable con todos los dominios.

SERPs de Google
Un resultado típico en Google, una SERP (Search Engine Result Page), está normalmente formado por los siguientes elementos.

Elemento #1: SEA (Google Ads)
La mayoría de las SERPs incluyen cuatro anuncios de Google por encima y hasta tres anuncios por debajo de los resultados de búsqueda orgánicos. Todos los anuncios están marcados con «Anuncio» a la izquierda de la URL.
Elemento #2: SEO
Entre los resultados de búsqueda pagados (Google Ads) se encuentran los resultados de búsqueda orgánicos. Por lo general, hay diez de estos resultados orgánicos o naturales en una página de resultados de búsqueda de Google.
Elemento #3: Universal Search
El tercer elemento de búsqueda es un cuadro de búsqueda universal. Los resultados aquí son tomados de otros productos de búsqueda de Google como noticias, imágenes y mapas, y se integran automáticamente en la página.
Otros SERP-Features
Además de los tres elementos descritos anteriormente, hay una serie de resultados SERP adicionales que, dependiendo del tipo de búsqueda, pueden aparecer en los resultados o no. He aquí algunos ejemplos:
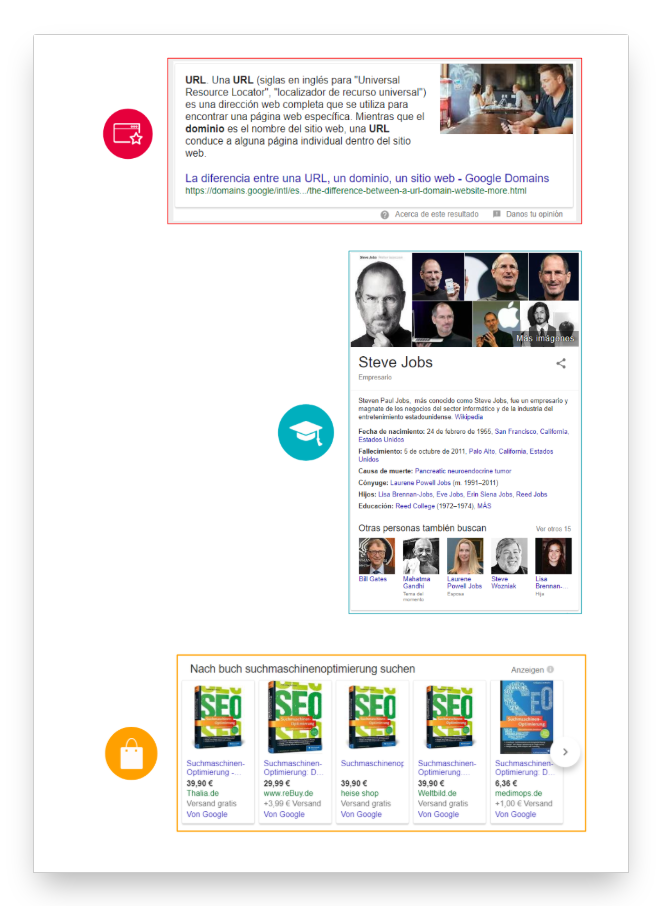
Elemento #4: Featured Snippet
Un fragmento enriquecido es un fragmento de SERP extendido. La información adicional puede aparecer en forma de texto, vídeo, listas o tablas. El featured snippet siempre se encontrará en la «posición cero», por encima de los resultados de la búsqueda orgánica.
Elemento #5: Knowledge-Graph
El knowledge graph aparecerá a la derecha de los resultados de la búsqueda en la versión de escritorio. Contiene una selección de información de lugares, personas y temas combinados por Google.
Elemento #6: Google Shopping
Google Shopping se encuentra normalmente a la derecha o encima de los resultados de búsqueda orgánicos. Las inserciones de Shopping se suelen colocar en forma de carrusel o en formato de baldosas.
Dominio, subdominio, host y URL
Una dirección de internet o dirección web consta de diferentes componentes.

- el protocolo utilizado: HTTP, también llamado Protocolo de Transferencia de Hipertexto. Se recomienda utilizar un protocolo cifrado, como HTTPS.
- El host o hostname: www.youtube.com
- El subdominio: www. (blog. , news. , support. , …)
- El nombre del dominio: youtube.com
- La extensión de las direcciones de internet, también llamado Top-Level-Domain (TLD): .com
- La ruta: /watch. Esto usualmente se refiere a un archivo o carpeta en el servidor web.
- Parámetros & Valor: Los parámetros son introducidos por «?” En el ejemplo anterior el nombre del parámetro es «v». A continuación sigue el valor del parámetro «QhcwLyyyEjOA». El esquema de ambos componentes es siempre nombre de parámetro = valor de parámetro.
En el lenguaje común sucede que cuando se habla de una URL, se refiere por lo general una ruta, a un directorio (https://www.sistrix.es/preguntale-a-sistrix/) o a un archivo (file:///C:/Users/d.garcia/Downloads/SEO-Analisis_con-el-IndicedeVisibilidad-SISTRIX.pdf).
Para más información, consulta el artículo «¿Cuál es la diferencia entre un URL, dominio, subdominio, Hostname, etc.?«
Factores de posicionamiento en Google
Cuando se trata de la búsqueda de Google y el algoritmo,hay varios factores que influyen en la composición y reproducción de los resultados de búsqueda. Encontrar una fuente fiable para el tema “los factores de posicionamiento de Google” no es trivial – hay una gran cantidad de información falsa circulando.
El mejor consejo es utilizar Google como fuente de información y recomendamos el siguiente documento. “Guía para principiantes sobre optimización para motores de búsqueda”.
Entre otras cosas, Google examina más de cerca los siguientes factores más destacados.
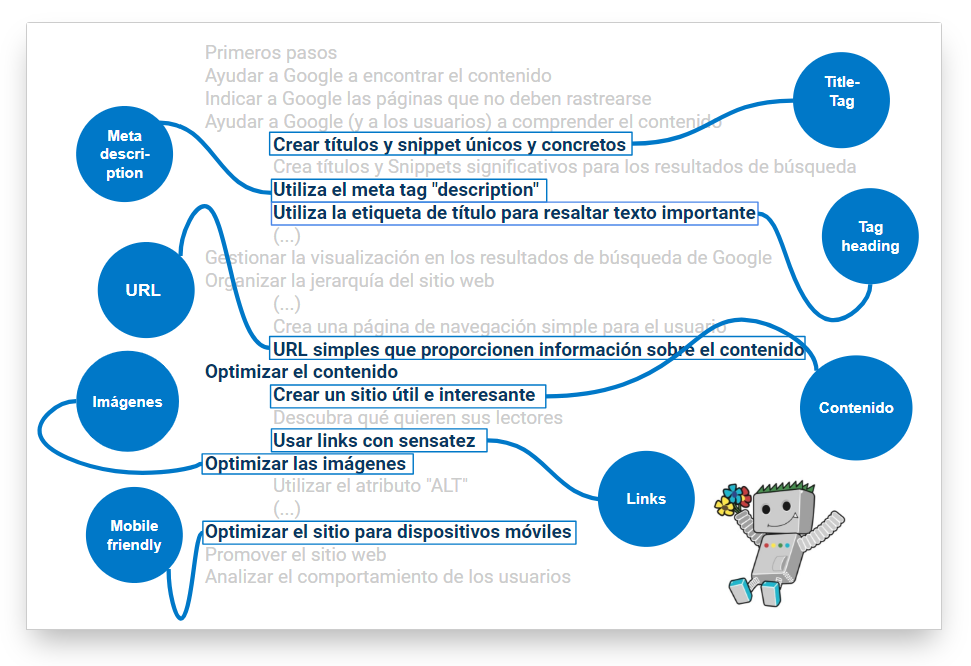
Google como fuente de éxito SEO
Para un SEO exitoso y sostenible, además de la «Guía de optimización en buscadores (SEO) para principiantes», todo el mundo debería tener en cuenta las directrices para webmasters y las directrices de calificación de calidad de la búsqueda. Aquí puedes encontrar consejos útiles del motor de búsqueda y lo que necesitas saber al buscar.
Echemos un vistazo a las “Directrices para webmasters” en este punto. ¿Qué criterios nombra Google? He aquí un breve extracto:
Ayuda a Google a encontrar el sitio
- Permitir el enlace de todas las páginas del sitio web.
- Usar el archivo Sitemap.
- Limitar el número de enlaces en una página.
- Usar la cabecera HTTP-Header If-Modified-Since.
- Gestionar el Crawling-Budget (robots.txt).
- Enviar el sitio web a Google.
Ayuda a Google a reconocer el sitio
- Crear sitios web útiles e informativos.
- Conocer la intención de búsqueda de nuestros usuarios y adaptar el sitio web a ella.
- Aplicar una clara jerarquía de páginas del sitio.
- Asegurar la conformidad de CMS a la rastreabilidad de páginas y enlaces.
- Asegurar la rastreabilidad de los archivos del sitio web (por ejemplo, CSS, archivo JavaScript, etc.).
- Evitar los ID de sesión y los parámetros de URL para los robots de búsqueda.
- Evitar rastrear enlaces publicitarios (por ejemplo, utilizando el archivo robots.txt o rel=»nofollow»)
Ayudar a los usuarios a utilizar el sitio
- Todos los enlaces deben remitir a Live-Websites.
- Optimizar el tiempo de carga del sitio web.
- Hacer el sitio web compatible con diferentes tipos de dispositivos.
- Diseño web para diferentes tipos de navegadores.
- Diseño de páginas web accesibles.
Principios básicos de las directrices de calidad
- Crear un sitio web para el usuario (no para el motor de búsqueda).
- No engañar a los usuarios (Cloaking).
- Evite triquiñuelas para el posicionamiento en los buscadores.
- Diseño de sitios web únicos.
Evitar los siguientes métodos
- Programas de intercambio de enlaces.
- Cloaking.
- Páginas puente.
- Links ocultos.
- Contenido copiado.
- (…)
¿Y de qué tratan las “Directrices de calificación de calidad”?
Esencialmente trata de los criterios de calidad para los cuales un sitio web es revisado manualmente por los calificadores de calidad de Google.
Esto permite a los SEO, webmasters y profesionales del marketing utilizar el documento de 160 páginas de Google para entender lo que es importante para el motor de búsqueda. El documento PDF completo lo puedes encontrar aquí.
Glosario
En SEO se utilizan muchos términos técnicos. Aquí encontrarás una lista de los términos más importantes y su definición ordenados alfabéticamente.
Atributo ”Alt”. Este es el nombre alternativo de una imagen. Google puede así reconocer la imagen. Las palabras clave más importantes o una descripción breve y concisa de la imagen se deben establecer como atributo “Alt”.
Atributo “hreflang”. Utilizando el atributo hreflang puedes asegurarte de que Google comprende el objetivo geográfico del sitio web y entrega el idioma correcto o la URL regional al usuario.
Backlinks. Los backlinks son referencias de un dominio a otro. Los usuarios pueden hacer clic en estos enlaces para acceder al dominio enlazado. Los backlinks siguen siendo un factor de posicionamiento importante para Google.
Canonical. Con la etiqueta canonical puedes definir una URL original. Si hay varias URLs con el mismo contenido, la etiqueta canonical indicará a Google la URL predeterminada. Esto ignora la(s) copia(s) del contenido duplicado.
Nota: solo hay unos pocos casos de uso legítimo de la etiqueta canonical. Por lo general, solo sirve como «parche» en los casos en que el problema real no puede ser resuelto.
Contenido duplicado. Cuando el mismo contenido se encuentra en múltiples URLs se conoce como contenido duplicado. Es importante evitarlo y asegurarse de que el contenido sólo sea accesible a través de una única URL. De lo contrario, Google no tiene claro qué URL debe clasificarse para ese contenido y qué señales de clasificación positivas deben atribuirse a esas URLs.
Conversión. Proceso de marketing online en el que se lleva a cabo una acción deseada, como una compra, una descarga o el envío de un registro.
Crawler. Software automatizado que rastrea, recupera e indexa páginas de la web.
Crawling. Proceso de búsqueda de sitios web nuevos o actualizados. Google sigue los enlaces, lee los mapas de sitio y utiliza muchos otros métodos para encontrar una URL. Google rastrea la web, busca nuevas páginas y las indexa según sea necesario.
Etiqueta “follow”. Con la etiqueta “follow” es posible decirle a los rastreadores de los motores de búsqueda que sigan los enlaces. Los enlaces externos que se siguen pasan link juice al sitio enlazado, una señal importante para Google, al sitio enlazado.
Etiqueta “nofollow”. Con esta etiqueta comunicamos al motor de búsqueda que no siga uno o más enlaces en una página. Por lo tanto, la página enlazada no se rastrea. Además, el valor del atributo nofollow no transmite un PageRank a la página de destino enlazada, por lo que el atributo nofollow nunca debe utilizarse para enlaces internos.
Featured Snippet. Conocido como “Fragmentos destacados o enriquecido” en castellano, se trata de un formato con el cual los usuarios reciben una respuesta corta y concisa a su búsqueda directamente en los resultados de búsqueda sin que el usuario tenga que navegar a través de diferentes páginas.
Google PageRank. Detrás del PageRank hay un algoritmo de Larry Page y Sergei Brin. Esto evalúa y pondera la reputación de una página según el número de enlaces entrantes. En los primeros días de Google confirmó la base del algoritmo para reproducir las páginas de resultados de búsqueda. El PageRank puede tomar un valor de cero a diez y sigue siendo utilizado internamente por Google pero ya no es accesible externamente.
Googlebot. Nombre común del rastreador de Google. Googlebot rastrea continuamente sitios web en internet.
HTTP- Códigos de estado. Se envía un código de estado HTTP desde cada servidor web como respuesta a cada petición HTTP o HTTPS. Los valores se dividen en rangos con diferentes significados. Por ejemplo el código 200 para indicar una petición de contenido exitosa.
Index (Índice). Todas las páginas web conocidas por Google se almacenan en el índice de Google. La entrada de índice de cada página describe su contenido y ubicación (URL). La indexación es el proceso mediante el cual Google recupera, lee y añade una página a su índice: «Hoy, Google indexó varias páginas de mi sitio.»
JavaScript. Lenguaje de codificación que permite una variedad de opciones de diseño e implementación como carruseles de imágenes e interactividad de páginas que se pueden incluir en una página web.
Meta-Tags. Los meta tags permiten a los webmasters proporcionar información sobre sus sitios web a los motores de búsqueda. Los meta tags se pueden utilizar para proporcionar información a una amplia gama de clientes. Cada sistema procesa sólo las etiquetas meta conocidas e ignora las etiquetas desconocidas. Los meta tags se colocan en la sección <head> del documento HTML.
Meta Description. La metaetiqueta «description» resume los temas tratados en la página para Google y otros motores de búsqueda. El título de una página puede incluir algunas palabras o una expresión. La metaetiqueta «description» de una página, en cambio, puede contener una o dos frases o incluso un párrafo corto. La Google Search Console proporciona un práctico informe de mejoras HTML que proporciona información sobre metaetiquetas de descripción demasiado cortas, largas o duplicadas. La misma información está disponible para las etiquetas <título>. Al igual que el tag <title>, el meta tag de descripción también se coloca dentro del elemento <head> del documento HTML.
Mobile-Friendly. Referente a la usabilidad de una página en el dispositivo móvil. Detrás de esto está la optimización del sitio web para smartphones.
Noindex. El valor de meta-robot «noindex» indica a un motor de búsqueda que no incluya la página en el índice de Google. La indexación de una página (URL) puede ser influenciada activamente por el webmaster.
Redirección-301. Una redirección 301 es un código de estado: HTTP 301. Movido permanentemente. Esto significa que el contenido de una URL se ha movido permanentemente y ahora se puede encontrar bajo una URL diferente (nueva).
Redirección-302. Una redirección 302 es un código de estado: HTTP 302. Movido temporalmente. Esto significa que el contenido de una URL se ha movido durante un tiempo limitado y temporalmente se puede encontrar bajo una URL diferente (nueva).
Robots.txt Un archivo robots.txt es un archivo en la raíz del sitio web que especifica las partes del sitio web a las que los rastreadores de los motores de búsqueda no deberían tener acceso. El archivo utiliza el Robots Exclusion Standard, un protocolo simple con algunas instrucciones que se comunican en el archivo de texto. Este archivo especifica la accesibilidad del sitio a secciones individuales y para diferentes tipos de rastreadores web.
SEO. Todas las medidas que se toman para aumentar la rentabilidad de un sitio web mediante la captación selectiva de visitantes a través de los resultados de búsqueda orgánicos de los motores de búsqueda.
SERP. La página SERP o Search Engine Result Page lista los resultados de la búsqueda (también conocidos como hits) a una consulta (palabra clave) en un motor de búsqueda (Google). Normalmente hay 10 hits naturales u orgánicos y de 3 a 5 anuncios de Google pagados.
SERP-Features. Este es el nombre que damos, dentro de la herramienta SISTRIX, a las diferentes formas de fragmentos que pueden aparecer en los resultados de búsqueda de Google. Algunos ejemplos son: imágenes, Adwords, cuadros de noticias, gráficos de conocimiento y mapas.
Tasa de rebote. Este valor muestra la frecuencia con la que un usuario ha abandonado un sitio web sin haber visitado más de una subpágina.
Textos ancla. El nombre de un enlace se llama texto de anclaje o a menudo también texto ancla. Coloquialmente hablando, este es el texto visible y clicable de un enlace.
Title-Tag. La etiqueta “title” representa el título de una URL y se muestra, por ejemplo, en las fichas del navegador web. En la mayoría de los casos, Google también muestra la etiqueta title como encabezado de un resultado de búsqueda (SERP). El contenido del elemento title de una página (URL) es un factor de clasificación importante y, por lo tanto, siempre debe establecerse.
TLD. La abreviatura TLD significa Top Level Domain (Dominio de nivel superior). Este es un componente dentro de una URL y se encuentra al final de la misma, por ejemplo www.sistrix.de, www.sistrix.com, www.sistrix.es, www.sistrix.it, etc. Las abreviaturas de los TLDs tienen diferentes significados: por ejemplo, las abreviaturas.de,. es o .it significan Top Level Domains específicos de cada país.
Fuentes relacionadas
Simplemente prueba la herramienta
Puedes probar la herramienta durante 7 días totalmente gratis